1 简介
随着应用服务的规模不断扩大,原有的垂直应用架构已无法满足产品的发展,几十个工程师在一个项目里并行开发不同的功能,开发效率不断降低,于是公司开始全面推进服务化进程,把团队内的大部分工程师主要精力全部都集中到服务化中。 服务化可以让每个工程师仅在自己负责的子项目中进行开发,提高了开发的效率,但是服务化同时也带来了其他问题:
- 无法知道每个服务的运行情况,例如,某一台服务它目前的 QPS 是多少?它的平均延迟是多少,99% 的延迟是多少,99.9% 的延迟又是多少?
- 某一个接口响应时间慢,如何定位是哪个方法引起的?
- 每个服务的负载是否均衡?
- 当服务出现抖动时,如何判断是 DB、Cache 还是下游服务引起的?
- DB 和 Cache 响应延迟是多少?
- 如何评估服务的容量,随着服务的调用量越来越大,这个服务需要多少机器来支撑?什么时候应该加机器?
目前已有的监控工具要么过于重量级,要么没有我想要的性能指标,不能满足我的 监控需求,为此,MyPerf4J诞生了,它用来来帮助我们监控服务的运行情况以及快速定位问题。
1.1 需求
MyPerf4J最基本的需求:
能统计处方法的
RPS、Avg、Min、Max、StdDev、TP90、TP95、TP99等指标可配置:
- 可指定统计某些类、某些方法
- 可指定不统计某些类、某些方法
拥有极致的性能
- 不影响应用的GC
- 不影响应用的RT
性能指标的处理可以定制化,例如:日志收集、上报给日志收集服务等。
1.2 指标
- Method Metrics
- RPS: 每秒请求数
- Count: 总请求数
- RT: 方法响应时间
- Avg: 方法平均响应时间
- Min: 方法最小响应时间
- Max: 方法最大响应时间
- StdDev: 方法响应时间的标准差
- TP50, TP90, TP95, TP99, TP999, TP9999, TP100
- TP: Top 百分数(Top Percentile)
- TP90: 在一个时间段内(如1分钟),统计该方法每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序,取第 90% 的那个值作为 TP90 值
JVM GC Metrics
- YoungGcCount: 一个时间片内累计 YoungGC 次数
- YoungGcTime: 一个时间片内累计 YoungGC 时间
- AvgYoungGcTime: 一个时间片内 YoungGC 平均时间
- FullGcCount: 一个时间片内累计 OldGC 次数
- FullGcTime: 一个时间片内累计 OldGC 时间
JVM Memory Metrics
- EdenUsed: 当前已经使用的Eden区内存量(以 KB 为单位)
- EdenUsedPercent: 当前已经使用的Eden区内存量占比
- SurvivorUsed: 当前已经使用的Survivor区内存量(以 KB 为单位)
- SurvivorUsedPercent: 当前已经使用的Survivor区内存量占比
- OldGenUsed: 当前已经使用的老年代内存量(以 KB 为单位)
- OldGenUsedPercent: 当前已经使用的老年代内存量占比
- HeapUsed: 当前已经使用的堆内内存量(以 KB 为单位)
- HeapUsedPercent: 当前已经使用的堆内内存量占比
- NonHeapUsed: 当前已经使用的非堆内内存量(以 KB 为单位)
- NonHeapUsedPercent: 当前已经使用的非堆内内存量占比
- PermGenUsed: 当前已经使用的永久代内存量(以 KB 为单位)
- PermGenUsedPercent: 当前已经使用的永久代内存量占比
- MetaspaceUsed: 当前已经使用的元数据区内存量(以 KB 为单位)
- MetaspaceUsedPercent: 当前已经使用的元数据区内存量占比
- CodeCacheUsed: 当前已经使用的 CodeCache区 内存量(以 KB 为单位)
- CodeCacheUsedPercent: 当前已经使用的 CodeCache区 内存量占比
JVM Thread Metrics
- TotalStarted: 自 JVM 启动以来启动过的线程数
- Active: 当前存活的线程数,包括守护线程和非守护线程
- Daemon: 当前存活的守护线程数
- Runnable: 正在 JVM 中执行的线程
- Blocked: 受阻塞并等待某个监视器锁的线程数
- Waiting: 无限期地等待另一个线程来执行某一特定操作的线程数
- TimedWaiting: 等待另一个线程来执行取决于指定等待时间的操作的线程处于这种状态数
- Terminated: 已退出的线程数
- Peak: 自 JVM 启动或峰值重置以来峰值活动线程计数
- New: 至今尚未启动的线程数
JVM ByteBuff Metrics
- Name: 缓存池名称
- Count: 缓存池中 buffer 的数量
- MemoryUsed: JVM 用于此缓冲池的内存估计值
- MemoryCapacity: 缓存池中所有 buffer 的总容量估计值
JVM Class Metrics
- Total: 自 JVM 开始执行到目前已经加载的类的总数
- Loaded: 当前加载到 JVM 中的类的数量
- Unloaded: 自 JVM 开始执行到目前已经卸载的类的总数
JVM Compilation Metrics
- Time: 一个时间片内累计编译时间
- TotalTime: 自 JVM 开始执行到目前累计的的总编译时间
JVM FileDescriptor Metrics
- OpenCount: 当前打开的文件句柄数
- OpenPercent: 当前打开的文件句柄数占最大文件句柄数的百分比
1.3 架构
MyPerf4j支持两种部署架构:
- 3.x及其之前

- 3.x
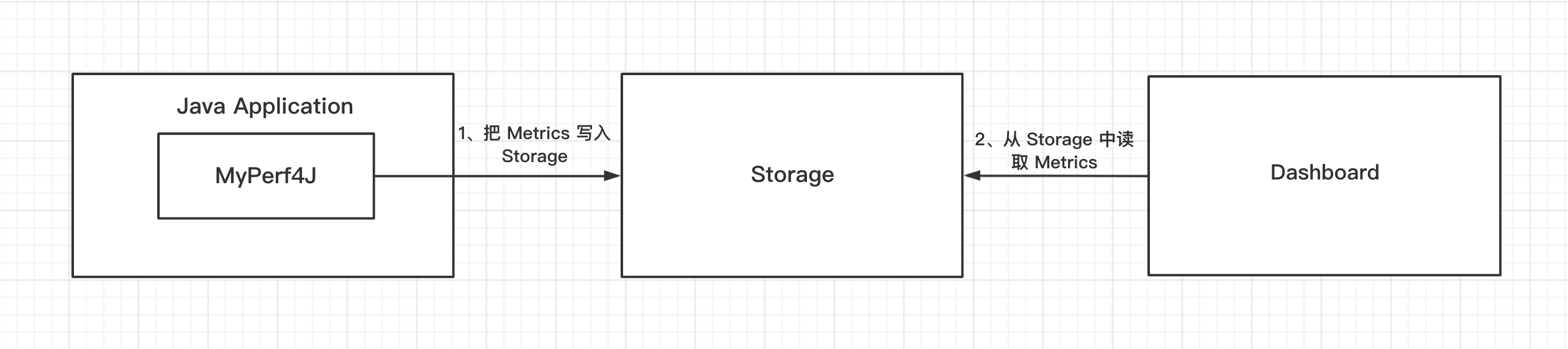
各组件说明
| 组件 | 说明 |
|---|---|
| Java Application | MyPerf4J 的运行容器 |
| MyPerf4J | Metrics 收集和统计 |
| Collector | 日志收集器 |
| Storage | 日志收集器 |
| Collector | 存储平台 |
| Dashboard | 可视化平台 |
各组件关系说明:
MyPerf4j 定时把指定时间片内的统计数据写入日志文件
Collector 从日志文件中读取统计数据,并写入Storage
Dashboard 从Storage 中读取数据并展示
注意,MyPerf4J项目 只提供MyPerf4J本身,其余组件需要用户自行选择。 这样做的优点如下:
- 保持 MyPerf4J 的精简
- 健壮性,不论是 Collector、Storage 还是 Dashboard 宕掉都不影响 MyPerf4J 的数据采集,也不丢失采集到的数据
- 多样性,Collector 可以是 Telegraf 也可以是 Filebeat;Storage 可以是 InfluxDB 也可以是 OpenTSDB; Dashboard 可以是 Grafana 也可以是 Chronograf
2 配置
这里主要是3.x配置,如果需要查看2.x配置,可以到 MyPerf4j 源码处查找。
MyPerf4J 默认提供了以下几个参数,用于控制 MyPerf4J 的行为:
| 属性 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| app_name | String | Y | 配置应用名称 | |
| debug | boolean | N | false | 配置是否开启 debug 模式,可配置为 true/false |
| http.server.port | int | N | 2048,2000,2040 | 配置 Http 服务器端口号,格式为:首选端口,备选最小端口,备选最大端口 |
| http.server.min_workers | int | N | 1 | 配置 Http 服务器的最小 work 线程数 |
| http.server.max_workers | int | N | 2 | 配置 Http 服务器的最大 work 线程数 |
| http.server.accept_count | int | N | 1024 | 配置 Http 服务器的最大排队请求数 |
| metrics.exporter | String | Y | log.stdout | 配置用于导出监控指标的 Exporter 的类型log.stdout:以标准格式化结构输出到 stdout.log,log.standard: 以标准格式化结构输出到磁盘,log.influxdb: 以 InfluxDB LineProtocol 格式输出到磁盘,http.influxdb:以 InfluxDB LineProtocol 格式发送至 InfluxDB server |
| metrics.log.method | String | N | data/logs/MyPerf4J/metrics.log | 配置方法性能监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.class_loading | String | N | NULL | 配置类加载监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.gc | String | N | NULL | 配置GC监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.memory | String | N | NULL | 配置内存监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.buff_pool | String | N | NULL | |
| metrics.log.thread | String | N | NULL | 配置线程监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.file_desc | String | N | NULL | 配置文件描述符监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.compilation | String | N | NULL | 配置编译时间监控指标的日志路径,NULL 表示丢弃收集到的监控指标 |
| metrics.log.rolling.time_unit | String | N | DAILY | 配置日志文件滚动时间间隔,分别有 MINUTELY、HOURLY 和 DAILY 三个值 |
| metrics.log.reserve.count | int | N | 7 | 配置历史日志文件保留个数 |
| metrics.time_slice.method | int | N | 60000 | 配置方法指标采集的时间片,单位为 ms,最小 1s,最大 600s |
| metrics.time_slice.jvm | int | N | 60000 | 配置方法指标采集的时间片,单位为 ms,最小 1s,最大 600s |
| metrics.method.show_params | boolean | N | false | 是否展示方法参数类型 |
| metrics.method.class_level_mapping | String | N | 配置 Java类的层级映射关系 | |
| recorder.mode String | N | rough | 配置 RecordMode,包含 accurate 和 rough 两个模式 | |
| recorder.size.timing_arr | int | N | 1000 | 配置通用的方法响应时间阈值,单位为 ms |
| recorder.size.timing_map | int | N | 16 | 配置通用的方法响应时间超出指定阈值的次数,仅在 RecorderMode=accurate 时有效 |
| recorders.backup_count | Int | N | 1 | 配置备用 Recorders 的数量,最小 1,最大 8;当你的应用程序拥有非常多的方法需要监控并且你配置的MilliTimeSlice 比较小时,可以适当的提高 BackupRecordersCount 的数值。 |
| filter.packages.include | String | Yes | 配置需要进行监控的包的前缀,支持多个包路径,每个包路径用英文 ‘;’ 分隔;可以使用 [] 表示包/类的集合,形如:com.demo.[p1,p2,p3];可以使用 * 表示通配符,形如:com..demo. | |
| filter.packages.exclude | String | N | “” | 配置不需要进行监控的包的前缀,支持多个包路径,每个包路径用英文 ‘;’ 分隔;可以使用 [] 表示包/类的集合,形如:com.demo.[p1,p2,p3];可以使用 * 表示通配符,形如:com..demo. |
| filter.methods.exclude | String | N | “” | 配置不需要进行监控的方法名,每个方法名用英文 ‘;’ 分隔 |
| filter.methods.exclude_private | boolean | N | true | 配置是否要排除私有方法,可配置为true/false |
| filter.class_loaders.exclude | String | N | “” | 配置不需要进行监控的 ClassLoader,支持多个 ClassLoader,每个 ClassLoader 路径用英文’;’分隔 |
| influxdb.version | String | N | 1.0 | 配置 InfluxDB 的 版本号 |
| influxdb.orgName | String | N | “” | 配置 InfluxDB 所属的组织名称,当 InfluxDB 为 v2.x 时为必填项 |
| influxdb.host | String | N | 127.0.0.1 | 配置 InfluxDB 的 IP 地址 |
| influxdb.port | int | N | 8086 | 配置 InfluxDB 的端口号 |
| influxdb.database | String | N | “” | 配置 InfluxDB 的数据库名 |
| influxdb.username | String | N | “” | 配置 InfluxDB 的用户名 |
| influxdb.password | String | N | “” | 配置 InfluxDB 的密码 |
| influxdb.conn_timeout | int | N | 3000 | 配置 InfluxDB 的连接超时时间,单位为 ms |
| influxdb.read_timeout | int | N | 5000 | 配置 InfluxDB 的读超时时间,单位为 ms |
2.1 关于 Rough模式 与 Accurate模式
- Rough 模式
- 精度略差,会把响应时间超过指定阈值的记录为’阈值+1’
- 更加节省内存,只使用数组来记录响应时间
- 速度略快一些,但计算 Metrics 的速度略慢一些
- 在 MyPerf4JPropFile 配置文件中指定 recorder.mode = rough
Accurate 模式
- 精度高,会记录所有的响应时间
- 相对耗费内存,使用数组 + Map 来记录响应时间
- 速度略慢一些,但计算 Metrics 的速度略快一些
- 默认
建议
- 对于有以下特征的应用,推荐使用 Rough 模式
- 内存敏感
- 精度要求不是特别高
- 对于有以下特征的应用,推荐使用 Accurate 模式
- 内存不敏感
- 精度要求特别高
- 方法响应时间范围比较广
- MyPerf4J 的版本号大于等于 2.8.0
2.2 关于包路径规则
filter.packages.include 和 filter.packages.exclude 目前支持以下三种规则:
com.demo.p1 代表包含以
com.demo.p1为前缀的所有包和类[] 表示集合的概念:例如,
com.demo.[p1,p2,p3]代表包含以com.demo.p1、com.demo.p2和com.demo.p3为前缀的所有包和类,等价于com.demo.p1;com.demo.p2;com.demo.p3* 表示通配符:可以指代零个或多个字符,例如:
com.*.demo.*
2.3 关于包路径规则
filter.methods.exclude 目前支持以下三种规则:
filter.methods.exclude = getId1代表排除所有方法名为 getId1 的方法filter.methods.exclude = DemoServiceImpl.getId1代表排除类 DemoServiceImpl 中所有方法名为 getId1 的方法filter.methods.exclude = DemoServiceImpl.getId1(long)代表排除类 DemoServiceImpl 中方法签名为 getId1(long) 的方法
2.4 关于 metrics.method.class_level_mapping 的使用规则
metrics.method.class_level_mapping 用于配置 Class 层级映射关系,格式为:LevelA:[classNameExpA1,classNameExpA2];LevelB:[classNameExpB1,classNameExpB2],以 metrics.method.class_level_mapping = Api:[*Api,*ApiImpl];Controller:[*Controller];为例:
Api:[*Api,*ApiImpl]代表所有以 Api 和 ApiImpl 结尾的类的层级为 ApiController:[*Controller]代表所有以 Controller 结尾的类的层级为 Controller

