1. 前言
不知道大家在项目中有没有遇到这样的场景,根据传入的类型,调用接口不同的实现类或者服务,比如根据文件的类型使用CSV解析器或者JSON解析器,在调用的客户端 一般都是用if else去做判断,比如类型为JSON,就用JSON解析器,那么如果新加一个类型的解析器,是不是调用的客户端还要修改?这显然太耦合了。
本文就介绍一种方法,服务定位模式Service Locator Pattern来解决,帮助我们消除紧耦合实现及其依赖性,并提出将服务与其具体类解耦。
2. 文件解析器
接下来通过一个例子来介绍如何使用Service Locator Pattern。
假设有一个从各种来源获取数据的应用程序,我们必须解析不同类型的文件,比如解析CSV文件和JSON 文件。
定义一个类型的枚举
1
2
3
4public enum ContentType {
JSON,
CSV
}定义一个解析的接口
1
2
3
4public interface Parser {
List parse(Reader reader);
}根据不同的文件类型编写不同的实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class CSVParser implements Parser{
public List parse(Reader reader) {
return null;
}
}
public class JSONParser implements Parser{
public List parse(Reader reader) {
return null;
}
}编写一个客户端,通过
switch case根据不同类型调用不同的实现类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class Client {
private Parser csvParser, jsonParser;
public Client(Parser csvParser, Parser jsonParser) {
this.csvParser = csvParser;
this.jsonParser = jsonParser;
}
public List getAll(ContentType contentType, Reader reader) {
//......
switch (contentType) {
case CSV:
return csvParser.parse(reader);
case JSON:
return jsonParser.parse(reader);
default:
break;
}
// ...........
return null;
}
}
可能大部份人首先想到的都是像上面一样的方式去实现,那么这样存在怎样的问题呢?
现在加入提出一个新需求支持XML文件类型,是不是客户端也要修改代码,然后在switch case中添加新的类型,这就导致客户端和不同的解析器紧密耦合。
那么有什么更好的方式呢?
3. 应用Service Locator Pattern
接下来使用服务定位模式Service Locator Pattern来改造上面的方法
定义服务定位器接口
ParserFactory,根据参数类型返回Parser1
2
3public interface ParserFactory {
Parser getParser(ContentType contentType);
}配置
ServiceLocatorFactoryBean使用ParserFactory作为服务定位器接口,ParserFactory这个接口不需要写实现类1
2
3
4
5
6
7
8
9
10
11
public class ParserConfig {
public FactoryBean serviceLocatorFactoryBean() {
ServiceLocatorFactoryBean factory = new ServiceLocatorFactoryBean();
//设置服务定位接口
factory.setServiceLocatorInterface(ParserFactory.class);
return factory;
}
}设置解析器Bean的名称为类型名称,方便服务定位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class CSVParser implements Parser {
public List parse(Reader reader) {
return null;
}
}
public class JSONParser implements Parser {
public List parse(Reader reader) {
return null;
}
}
public class XmlParser implements Parser{
public List parse(Reader reader) {
return null;
}
}修改枚举,添加XML类型
1
2
3
4
5public enum ContentType {
JSON,
CSV,
XML
}最后修改客户端调用,直接根据类型调用对应的解析器,去掉了
switch case1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class Client {
private ParserFactory parserFactory;
public Client(ParserFactory parserFactory) {
this.parserFactory = parserFactory;
}
public List getAll(ContentType contentType, Reader reader) {
//..............
//关键点,直接根据类型获取
return parserFactory.getParser(contentType).parse(reader);
}
}
这样就实现了,如果再添加新的类型,只需要扩展添加新的解析器就行,再也不用修改客户端了,满足开闭原则。
如果觉得Bean的名称直接使用类型怪怪的,可以建议按照下面的方式来
1 | public enum ContentType { |
4. 剖析Service Locator Pattern
服务定位器模式消除了客户端对具体实现的依赖。以下引自 Martin Fowler 的文章总结了核心思想:“服务定位器背后的基本思想是拥有一个知道如何获取应用程序可能需要的所有服务的对象。因此,此应用程序的服务定位器将有一个在需要时返回“服务”的方法。”
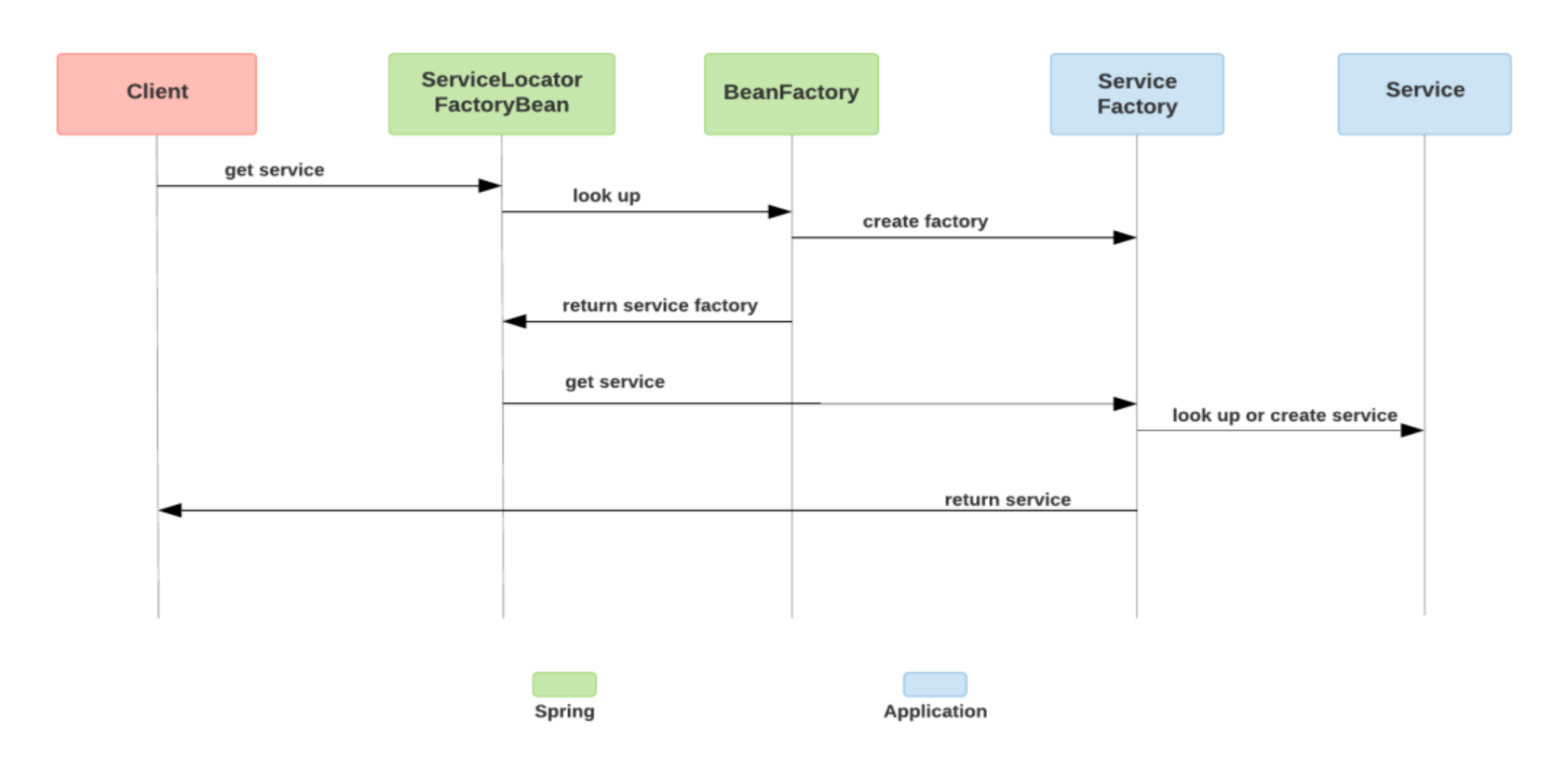
Spring 的ServiceLocatorFactoryBean实现了 FactoryBean接口,创建了Service Factory服务工厂Bean。
5. 总结
我们通过使用服务定位器模式实现了一种扩展 Spring 控制反转的绝妙方法。它帮助我们解决了依赖注入未提供最佳解决方案的用例。也就是说,依赖注入仍然是首选,并且在大多数情况下不应使用服务定位器来替代依赖注入。

