目录
1. 接口幂等性
2. SpringBoot 防重Token令牌方案
3. 接口数据安全方案
4. 接口性能优化方案
5. 接口设计的锦囊
1. 接口幂等性
1.1 幂等性描述
幂等是一个数据和计算机学概念,在数学中某一元运算为幂等时,作用多次和作用一次的结果相同
在数学中,幂等用函数表达式就是:f(x) = f(f(x))
1.2 接口幂等性
在HTTP/1.1中,对幂等性进行类定义,它描述一次和多次请求某个资源对资源本身应该具有同样的结果(网络超时等问题除外),
即多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致。
幂等性指的是作用于结果而非资源本身。例如,HTTP GET方法可能会每次得到不同的返回内容,但并不影响资源。
1.3 为什么需要实现幂等性
在接口调用时一般情况下都能正常返回信息不会出现重复提交,不过出现以下几种情况会有问题,如:
前端重复提交表单:比如用户注册时,因网络波动没有及时对用户做出提交成功响应,致使用户认为没有提交成功,然后多次进行提交操作,这时就会发生重复提交请求
用户恶意刷单:比如用户投票,如果用户针对一个内容重复提交投票,接口接收到用户重复提交的投票信息,影响实际的计算结果
接口超时重复提交:如果存在超时重试机制,尤其是第三方调用接口时,为了防止网络波动超时等造成的请求失败,都会添加重试机制,导致一个请求多次提交
消息进行重复消费:当使用MQ消息中间件时,如果发生消息中间件出现错误为即使提交消费消息,导致发生重复消费;
使用幂等性最大的优势在于使接口保证任何幂等性操作,避免因重试等造成系统未知问题。

1.4 幂等性对系统的影响
幂等性是为了简化客户端逻辑处理,能防止重复提交等操作,但也额外增加了服务端业务逻辑复杂性,主要是
把并行执行的功能改成了串行,降低了执行效率
增加了额外控制幂等的业务代码,使原本的业务功能复杂化
所以我们需要根据实际的业务场景来考虑是否引入幂等性
1.5 Restful API 接口的幂等性
现在流行的Restful 推荐的几种HTTP方法中幂等性如下:
| 类型 | 是否幂等 | 描述 |
|---|---|---|
| HEAD | 是 | Head不含有呈现数据,仅时HTTP头信息,head方法常用来做探活使用 |
| GET | 是 | Get 方法用于获取资源。其一般不会也不应当对系统资源进行改变,所以是幂等的 |
| POST | 否 | Post 方法一般用于创建新的资源。其每次执行都会新增数据,所以不是幂等的 |
| PUT | - | Put 方法一般用于更新资源。该操作则分情况来判断是不是满足幂等,更新操作中直接根据某个值进行更新,也能保持幂等。不过执行累加操作的更新是非幂等 |
| DELETE | - | Delete 方法一般用于删除资源。该操作则分情况来判断是不是满足幂等,当根据唯一值进行删除时,删除同一个数据多次执行效果一样。不过需要注意,带查询条件的删除则就不一定满足幂等了。例如在根据条件删除一批数据后,这时候新增加了一条数据也满足条件,然后又执行了一次删除,那么将会导致新增加的这条满足条件数据也被删除。 |
| OPTIONS | 是 | 主要用于获取当前URL所支持的方法,也是有点像查询 |
1.6 如何设计幂等
幂等意味着一条请求的唯一性,无论上面哪个方,都需要一个全局ID去标记这个请求是独一无二的。
- 数据库唯一索引控制幂等,那唯一索引是唯一的
- 数据库主键控制幂等, 那么主键是唯一的
全局唯一ID
下面Demo防重Token令牌方案使用的是UUID,但是UUID的缺点比较明显,字符串占用的空间比较大,生成的ID过于随机,可读性差,而且没有递增。
我们还可以使用Snowflake雪花算法 生成唯一ID
雪花算法是一种生成分布式全局ID的算法,生成的ID称为
Snowflakes IDs
一个SnowflakesID有64位:
- 第1位: Java中long的最高位是符号位,正数为0,负数是1,一般生成的ID都是正数,所以默认为0
- 第2-42位:时间戳,表示了自选定的时期以来的毫秒数
- 第43-52位:计算机ID,防止冲突
- 第53-64位:每台及其上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID
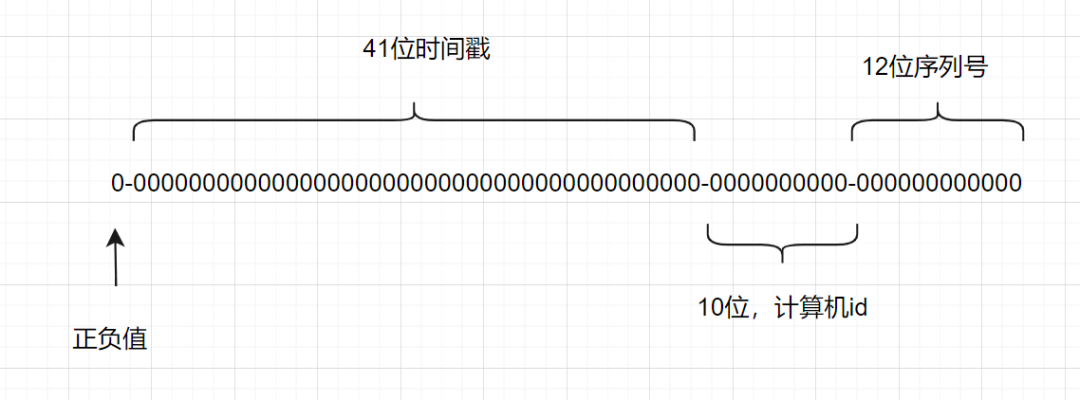
全局唯一ID还可以使用百度的Uidgenerator、美团的leaf
幂等设计的基本流程
幂等处理的过程,其实就是过滤以下已经收到的请求,然后判断请求是否之前收到过,把请求存储起来,收到请求时,先查下存储记录,记录存在就返回上次的结果,不存在就处理请求。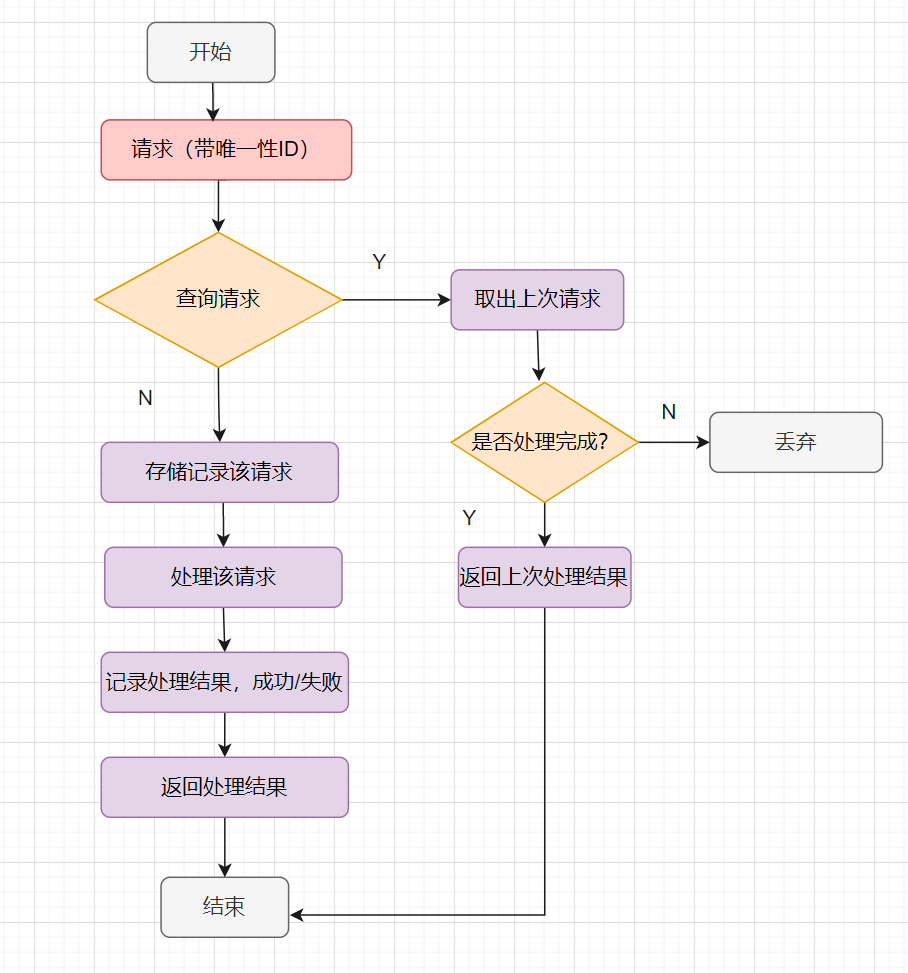
1.7 实现幂等的方案
方案1:数据库唯一主键
- 描述
利用数据库主键唯一约束的特性,依赖来说唯一主键比较适用于插入时的幂等性,其能保证一张表只能存在一条带该唯一主键的记录
使用数据库唯一主键完成幂等性时需要注意的是,该主键一般来说并不是使用数据库自增主键,而是使用分布式ID作为主键,这样才能保证在分布式环境下ID的全局一致性
- 使用操作
- 插入
- 删除
- 使用限制
- 需要生成全局唯一主键ID
- 主要流程
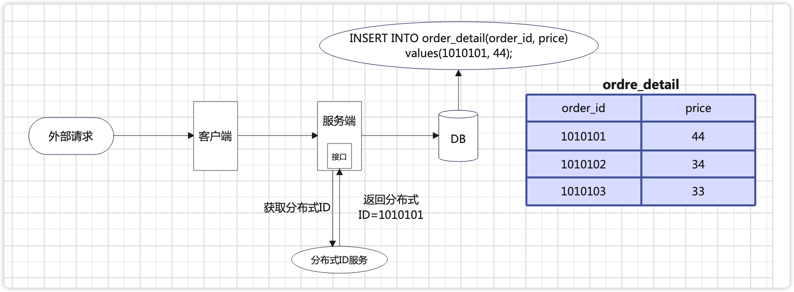
分布式ID服务可以使用Snowflake算法、数据库号段模式、Redis自增等方式生成;
方案2:数据库乐观锁
乐观锁:在操作数据时,非常乐观,认为别人不再同时在修改数据,因此乐观锁不会上锁,只是在执行更新的时候判断以下,在此期间是否别人修改了数据
描述
一般只适用于更新操作的过程,在表中增加version版本字段,每次对该表的这条数据更新时,都会带上上次更新后的version值
使用操作
- 更新
使用限制
- 需要在业务表中添加额外字段
主要流程
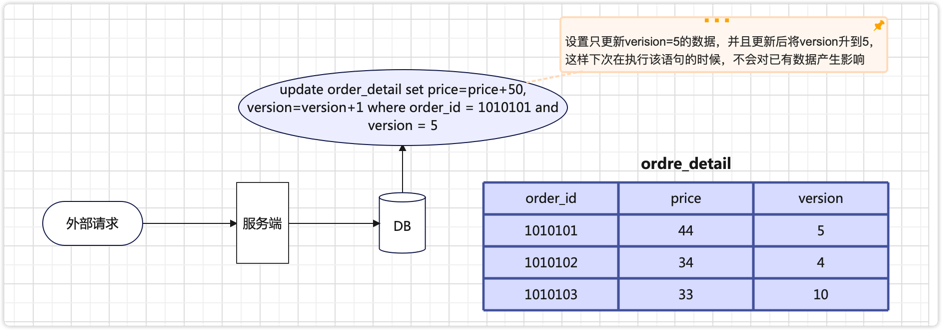
更新数据前,先查下数据,查出版本号为
version = 5然后使用
version=5和order_id=1010101一起作为条件去更新
为什么版本号建议自增呢?
因为乐观锁存在ABA的问题,如果version版本一直是自增就不会出现ABA的情况了。
ABA问题:一个线程先读取共享内存数据值A,随后因某种原因,线程暂时挂起,同时另一个线程临时将共享内存数据值先改为B,随后又改回为A。随后挂起线程恢复,并通过CAS比较,最终比较结果将会无变化。这样会通过检查,这就是ABA问题。 在CAS比较前会读取原始数据,随后进行原子CAS操作。这个间隙之间由于并发操作,最终可能会带来问题
相当于是只关心共享变量的起始值和结束值,而不关心过程中共享变量是否被其他线程动过。
方案3:防重Token令牌
描述
针对客户端连续点击或者调用方的超时重试等情况,例如提交订单,此种操作就可以用 Token 的机制实现防止重复提交。简单的说就是调用方在调用接口的时候先向后端请求一个全局 ID(Token),请求的时候携带这个全局 ID 一起请求(Token 最好将其放到 Headers 中),后端需要对这个 Token 作为 Key,用户信息作为 Value 到 Redis 中进行键值内容校验,如果 Key 存在且 Value 匹配就执行删除命令,然后正常执行后面的业务逻辑。如果不存在对应的 Key 或 Value 不匹配就返回重复执行的错误信息,这样来保证幂等操作
使用操作
- 更新
- 插入
使用限制
需要生成全局唯一 Token串
需要使用Redis进行数据校验
主要流程
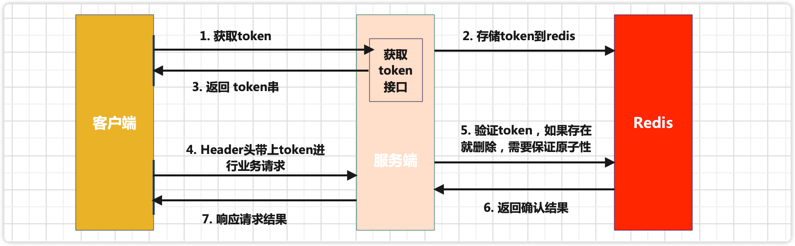
Token可以是一个序列号,也可以是分布式ID或者UUID串- 验证成功:说明存在该token,是第一次调用接口,可以执行后面的业务代码,同时在redis中删除该token
- 验证失败:说明存在该token,是重复调用接口,不可以执行后面的业务代码;
注意,在并发情况下,执行 Redis 查找数据与删除需要保证原子性,否则很可能在并发下无法保证幂等性。其实现方法可以使用分布式锁或者使用 Lua 表达式来注销查询与删除操作。
方案4:下游传递唯一序列号
描述
所谓请求序列号,其实就是每次向服务端请求时候附带一个短时间内唯一不重复的序列号,该序列号可以是一个有序 ID,也可以是一个订单号,一般由下游生成,在调用上游服务端接口时附加该序列号和用于认证的 ID。 当上游服务器收到请求信息后拿取该 序列号 和下游 认证ID 进行组合,形成用于操作 Redis 的 Key,然后到 Redis 中查询是否存在对应的 Key 的键值对,根据其结果:
- 如果存在,就说明已经对该下游的该序列号的请求进行了业务处理,这时可以直接响应重复请求的错误信息。
- 如果不存在,就以该 Key 作为 Redis 的键,以下游关键信息作为存储的值(例如下游商传递的一些业务逻辑信息),将该键值对存储到 Redis 中 ,然后再正常执行对应的业务逻辑即可。
使用操作
- 更新
- 插入
- 删除
使用限制
- 需要第三方传递唯一序列号
- 需要使用Redis进行数据校验
- 主要流程
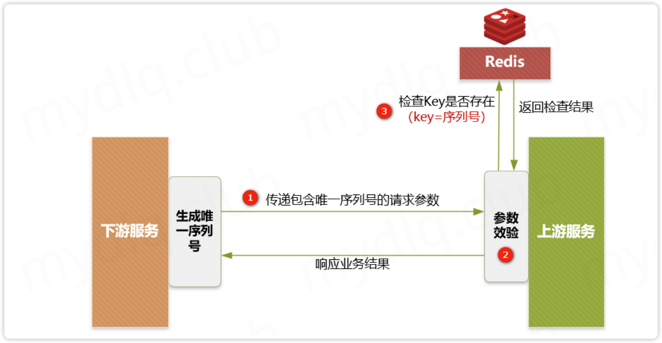 ① 下游服务生成分布式 ID 作为序列号,然后执行请求调用上游接口,并附带“唯一序列号”与请求的“认证凭据ID”。
① 下游服务生成分布式 ID 作为序列号,然后执行请求调用上游接口,并附带“唯一序列号”与请求的“认证凭据ID”。
② 上游服务进行安全效验,检测下游传递的参数中是否存在“序列号”和“凭据ID”。
③ 上游服务到 Redis 中检测是否存在对应的“序列号”与“认证ID”组成的 Key,如果存在就抛出重复执行的异常信息,然后响应下游对应的错误信息。如果不存在就以该“序列号”和“认证ID”组合作为 Key,以下游关键信息作为 Value,进而存储到 Redis 中,然后正常执行接来来的业务逻辑。上面步骤中插入数据到 Redis 一定要设置过期时间。这样能保证在这个时间范围内,如果重复调用接口,则能够进行判断识别。如果不设置过期时间,很可能导致数据无限量的存入 Redis,致使 Redis 不能正常工作。
方案5:状态机幂等
- 描述
很多业务表都是有状态的,比如转账流水表就会有0-待处理,1-处理中,2-成功,3失败,转账流水更新时,都会涉及流水状态更新,即涉及状态机。
比如转账成功后,把处理中的流水更新为成功状态1
update trans_flow set status = 2 where biz_seq='123' and status = 1;
- 主要流程
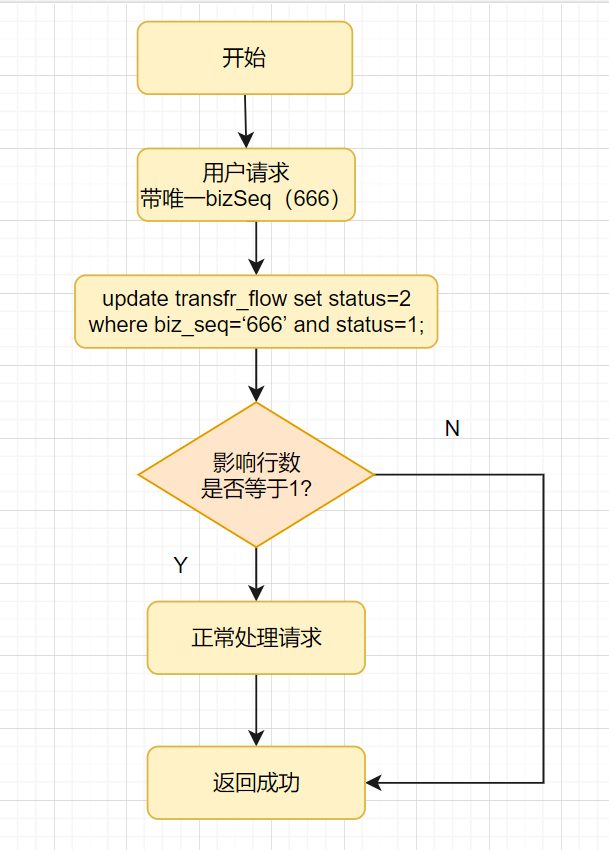
- 第1次请求来时,bizSeq流水号是 666,该流水的状态是处理中,值是 1,要更新为2-成功的状态,所以该update语句可以正常更新数据,sql执行结果的影响行数是1,流水状态最后变成了2。
- 第2请求也过来了,如果它的流水号还是 666,因为该流水状态已经2-成功的状态了,所以更新结果是0,不会再处理业务逻辑,接口直接返回。
- 伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Rsp idempotentTransfer(Request req){
String bizSeq = req.getBizSeq();
int rows= "update transfr_flow set status=2 where biz_seq=#{bizSeq} and status=1;"
if(rows==1){
log.info(“更新成功,可以处理该请求”);
//其他业务逻辑处理
return rsp;
}else if(rows==0){
log.info(“更新不成功,不处理该请求”);
//不处理,直接返回
return rsp;
}
log.warn("数据异常")
return rsp:
}
方案6:悲观锁
悲观锁:通俗的讲,就是每次去操作数据时,都会觉得别人中途会修改,所以每次拿到数据的时候都会上锁;官方点讲就是:共享资源每次只给一个线程使用,其他线程阻塞,用完后再把资源转为其他线程。
- 业务场景
1
假设先查处订单,如果查到的时处理中状态,就处理完业务,然后更新订单状态为完成,如果查到订单状态不是处理中状态,则直接返回
- 伪代码 这种场景时非原子操作的,在高并发环境下,可能会造成一个业务被执行两次的问题
1
2
3
4
5
6
7
8
9
10begin; # 1.开始事务
select * from order where order_id='666' -- 查询订单,判断状态
-- 0-待处理,1-处理中,2-成功,3失败
if(status != 处理中){
//非处理中状态,直接返回;
return ;
}
## 处理业务逻辑
update order set status='完成' where order_id='666' # 更新完成
commit; -- 5.提交事务
可以使用数据库悲观锁(select … for update)来解决这个问题当一个请求A在执行时,而另一个请求B也开始状态判断的操作,因为请求A还未来得及更改状态,所以请求B也能执行成功,这就导致一个业务被执行了两次。
1
2
3
4
5
6
7
8
9
10begin; -- 1.开始事务
select * from order where order_id='666' for update -- 查询订单,判断状态,锁住这条记录
-- 0-待处理,1-处理中,2-成功,3失败
if(status != 处理中){
-- 非处理中状态,直接返回;
return ;
}
## 处理业务逻辑
update order set status='完成' where order_id='666' -- 更新完成
commit; -- 5.提交事务- 这里面
order_id需要时索引或主键,如果不是索引或主键,会锁表;相关内容可以查看博客《 select … for update表锁还是行锁 》 - 悲观锁在统一事务操作过程中,锁住了一行数据,别的请求只能等待,如果当前事务耗时比较长,就很影响接口性能,所以一般不建议使用悲观锁来做幂等
- 这里面
方案7:分布式锁
描述
分布式锁实现幂等性的逻辑就是:请求过来时,先去尝试获取分布式锁,如果获得成功就执行业务逻辑,反之获取失败的话,就舍弃请求直接返回成功
主要流程

- 分布式锁可以使用redis、zookeeper; redis可能会好一点,轻量级
- redis分布式锁,可以使用命令
set ex px nx + 唯一流水号实现,分布式锁的key 必须为业务的唯一标识 - Redis执行设置key的动作时,需要设置过期时间,太长会占存储空间,太短拦截不了重复请求
总结
- 对于下单等存在唯一主键的可以使用”唯一主键方案”的方式实现
- 对于更新订单状态等相关的更新场景操作,可以使用”乐观锁方案”
- 对于上下游这种,下游请求上游,上游服务可以使用”下游传递唯一序列号方案”更为合理
- 类似于前端重复提交、重复下单、没有唯一ID号的场景,可以通过token与Redis配置的”防重Token方案”更为快捷
| 方案 | 适用方法 | 复杂度 | 缺点 |
|---|---|---|---|
| 数据库唯一主键 | 插入、删除 | 简单 | 只能用于存在唯一主键的场景 |
| 数据库乐观锁 | 更新 | 简单 | 只能用于更新操作,表中需要添加额外字段 |
| 请求序列号 | 插入、删除、更新 | 简单 | 1. 需要保证下游生成唯一序列号; 2. 需要Redis存储序列号 |
| 防重Token令牌 | 插入、更新、删除 | 适中 | 需要Redis存储序列号 |
| 悲观锁 | 更新、删除 | 适中 | 如果当前事务耗时比较长,就很影响接口性能 |
2. SpringBoot 防重Token令牌方案
该方案能保证在不同请求动作下的幂等性,实现逻辑可以看上面写的”防重Token令牌”方案;
2.1 引入相关依赖
1 |
|
2.2 配置文件
1 | # 配置redis连接参数 |
2.3 Token获取/验证接口
创建用于操作Token相关的Service类,包含创建token以及验证方法,其中:
Token创建: 使用UUID工具创建token串,设置
IDEMPOTENT_TOKEN_PREFIX:+token串作为key,以用户信息作为value,存入Redis;Token验证:接口Token串参数,加上前缀生成key,再传入用户信息value,使用Lua表达式(Lua表达式能保证命令执行的原子性)进行查找对应的key和value,执行完成后验证命令的返回结果,如果不为空且非0则验证成功,反之则失败;
1 | /** |
2.4 创建Controller
创建用于测试的 Controller 类,里面有获取 Token 与测试接口幂等性的接口,内容如下:
1 | /** |
2.5 创建Springboot启动类
1 |
|
2.6 创建测试类
测试多次访问同一个接口,是否只有第一次执行成功
1 |
|
调用结果返回如下:
1 | [main] org.example.IdempotentTest : 获取的token串:ed965e9e-42ce-4865-a1fd-25d13ad5544b |
3. 接口数据安全方案
3.1 数据加密,防止报文明文传输
数据在网络传输过程中,很容易被抓包,如果使用的时http协议,因为他是明文传输的,用户的数据很容易被别人获取,所以需要对数据加密。
3.1.1 加密方式
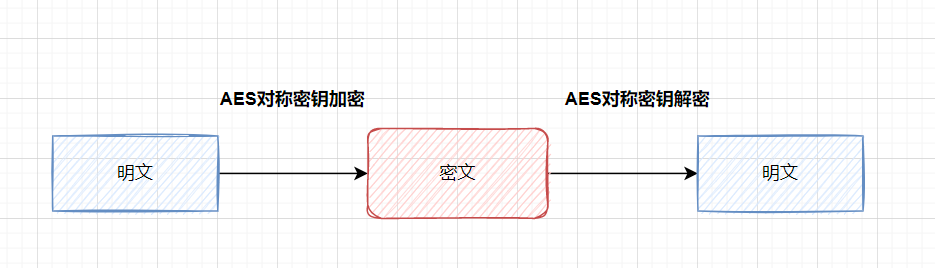
常见搭的实现方式,就是对关键字段加密,比如登陆接口对密码加密。一般采用的是:对称加密算法(AES
来加解密,或者哈希算法(MD5)
对称加密:加密和揭秘使用相同的密钥的加密算法
非对称加密:非对称加密算法需要两个密钥(公开密钥和私有密钥)。公钥与私钥是成对存在的,如果用公钥对数据进行加密,只有对应的私钥才能解密。
更安全的做法,就是用非对称加密算法(RSA、SM2),公钥加密、私钥解密。
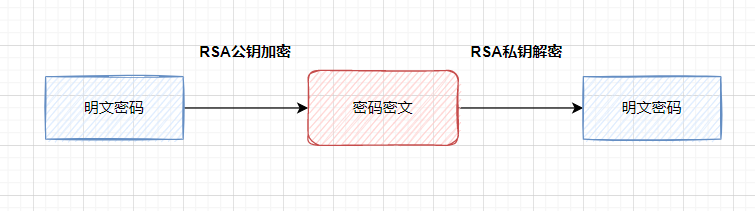
3.1.2 HTTPS安全协议
如果想对所有字段都加密的话,一般都推荐使用HTTPS协议,https就是在http和tcp之间添加一层加密层SSL。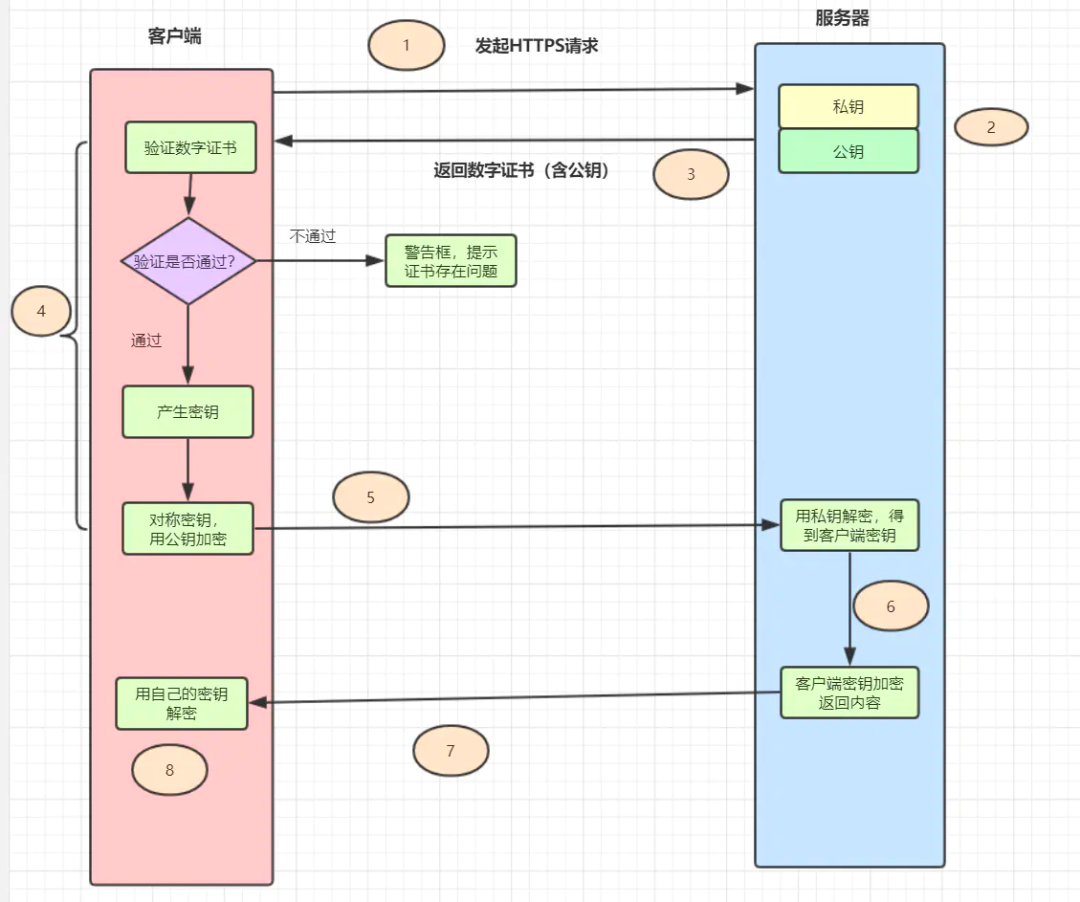
- 客户端发起Https请求,连接到服务器的443端口。
- 服务器必须要有一套数字证书(证书内容有公钥、证书颁发机构、失效日期等)。
- 服务器将自己的数字证书发送给客户端(公钥在证书里面,私钥由服务器持有)。
- 客户端收到数字证书之后,会验证证书的合法性。如果证书验证通过,就会生成一个随机的对称密钥,用证书的公钥加密。
- 客户端将公钥加密后的密钥发送到服务器。
- 服务器接收到客户端发来的密文密钥之后,用自己之前保留的私钥对其进行非对称解密,解密之后就得到客户端的密钥,然后用客户端密钥对返回数据进行对称加密,酱紫传输的数据都是密文啦。
- 服务器将加密后的密文返回到客户端。
- 客户端收到后,用自己的密钥对其进行对称解密,得到服务器返回的数据。
基本的日常业务,数据传输加密这块的话,用https就可以,如果安全性要求较高的,比如登陆注册这些,需要传输密码的,密码就可以使用RSA等非对称加密算法,对密码加密。如果你的业务,安全性要求很高,你可以模拟https这个流程,对报文,再做一次加解密。
3.2 数据加签验签
数据报文加签验签,就是保证数据传输安全的常用手段,它可以保证数据在传输过程中不给篡改。
3.2.1 什么是加签验签
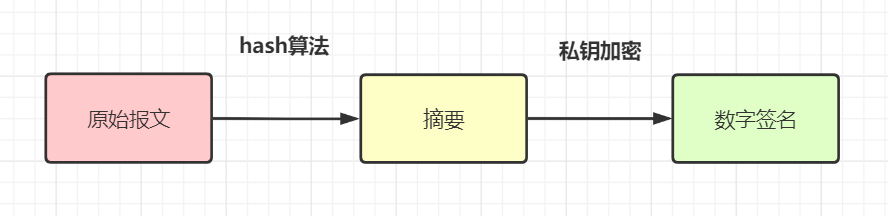
- 数据加签:用Hash算法(md5、SHA-256)把原始请求参数生成报文摘要,然后用私钥对这个摘要加密,就得到这个报文对应的数字签名sign(这个过程就是加签)。通常来说,请求方会把数字签名和报文原文一并发送给接收方
- 验签:接收防拿到原始报文和数字签名sign后,用同一个hash算法(比如都用MD5)从报文中生成摘要A,然后用对方提供的公钥对数字签名进行解密,得到摘要B,对比A和B是否相同,就可以知道报文是否被篡改过。
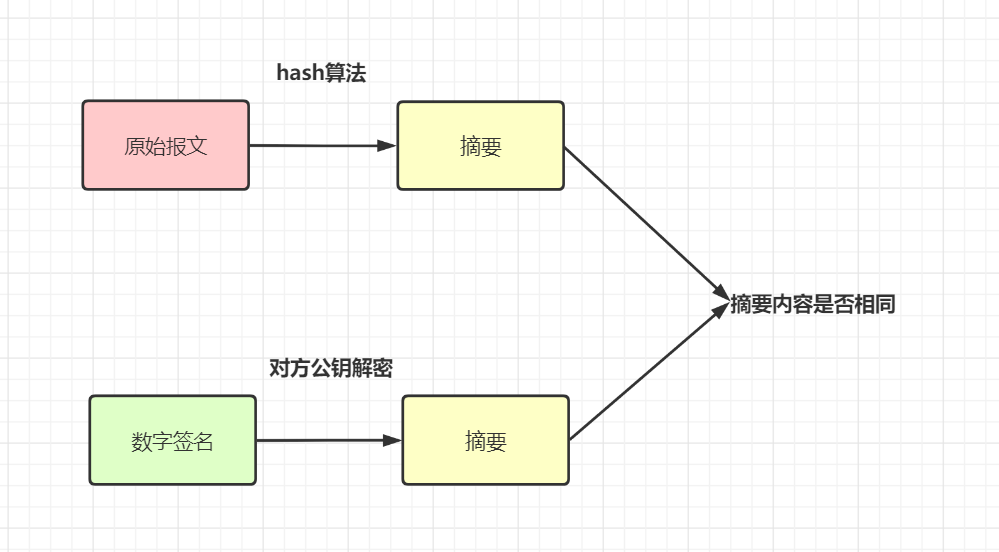
通俗一点讲:就是把请求参数,按照一定规则,利用hash算法+加密算法生成一个唯一标签sign。验签的话,就是把请求参数按照相同的规则处理,再用相同的hash算法,和对应的密钥解密处理,以对比这个签名是否一致。
3.2.2 有了Https,为什么还要加签验签
加签验签主要是防止数据在传输过程中被篡改,那如果都用了Https协议加密数据了,为啥还需要加签验签?
数据在传输过程中被加密了,理论上,即使被抓包,数据也不会被篡改,但是HTTPS不是绝对的安全,另外Https加密的部分只是在外网,然后很对服务是内网相互跳转的,捡钱也可以保证在这里不被中间人篡改;
3.3 token 授权认证机制
日常开发中,我们的网站或者App都是需要用户登录的,那么如果是非登录接口,如何确保安全,如何确认用户身份?可以使用token授权机制
用户在客户端输入用户名和密码,点击登录后,服务器会校验密码,然后返回客户端一个token,并将token 以键值对的形式存放在缓存中(一般为Redis)后续用户访问需要授权的模块的操作时,都携带这个token,服务器接收到请求后,先对token验证,如果token存在,才表名时合法请求
这个其实用过jwt的同学应该都会清楚这个流程。
3.3.1 token授权认证方案

- 用户输入用户名和密码,发起登录请求
- 服务端校验密码,如果校验通过,生成全局唯一token
- 将token存在redis中,key是token, value为用户ID,设置一个过期时间
- 将token返回给客户端
- 用户发起其他业务请求时,需要携带这个token
- 后台服务统一拦截接口请求,进行token有效性验证,并从中获取用户信息,供后续业务逻辑使用,如果token不存在,请求无效。
3.3.2 如何保证token的安全?token被劫持呢?
比如说,如果我拿到了token,是不是就可以调用服务端的任何接口?可以从下面几方面考虑
- token设置合理的有效期
- 使用https协议
- token可以再次加密
- 如果访问的时敏感信息,单纯的加token是不够的,通常还会设置白名单
3.4 时间戳timestamp超时机制
数据是很容易抓包,假设我们使用了https和加签,即使中间人抓到了数据报文,他也看不到真实数据,但是也要避免那种使用抓取的数据包进行恶意请求(如DOS攻击),以搞垮系统
这里我们可以引入时间戳超时机制,来保证接口安全。用户每次请求都带上当前时间的时间戳timestamp,服务器收到timestamp后,解密,验签通过后,与服务器当前时间进行比对,如果时间大于一定的时间(比如5分钟),则任务该请求无效。
3.5 timestamp+nonce方案防止重放攻击
时间戳超时机制也是有漏洞的,如果是在时间差内,黑客进行重放攻击,那么就可以使用timestamp + nonce方案了
nonce指唯一的随机字符串,用来标识每个被清明的请求,我们可以将每次请求的nonce参数存储到一个set集合中,或者使用json格式存储到数据库或缓存中,每次处理http请求是,首先判断请求的nonce参数是否在该集合中,如果存在则认为非法请求。
然而对于服务器而言, 永久保存nonce的代价非常大,可以通过timestamp来优化,因为timestamp参数对于超过5min的请求,都认为非法请求,所以我们只需要存储5min内的nonce参数集合即可。
3.6 限流机制
如果用户本来就是真实用户,他恶意频繁调用接口,那么这个时候就需要接入限流了。
常用的限流算法有: 令牌桶和漏桶算法
可以使用Guava的RateLimiter单机版限流,也可以使用Redis分布式限流,还可以使用阿里开源组件sentinel限流。比如:一分钟可以接受多少次请求
3.7 黑名单机制
如果发现了真实用户恶意请求,你可以搞个黑名单机制,把该用户拉黑。一般情况,会有些竞争对手,或者不坏好意的用户,想搞你的系统的。所以,为了保证安全,一般我们的业务系统,需要有个黑名单机制。对于黑名单发起的请求,直接返回错误码好了
3.8 白名单机制
有了黑名单机制,也可以搞个白名单机制啦。第三方需要接入我们的系统时,是需要提前申请网络白名单的。申请个IP网络白名单,只有白名单里面的请求,才可以访问我们的系统。
3.9 数据脱敏掩码
对于密码,或者手机号、身份证这些敏感信息,一般都需要脱敏掩码再展示的,如果是密码,还需要加密再保存到数据库。
对于手机号、身份证信息这些,日常开发中,在日志排查时,看到的都应该是掩码的。目的就是尽量不泄漏这些用户信息,虽然能看日志的只是开发和运维,但是还是需要防一下,做掩码处理。
对于密码保存到数据库,我们肯定不能直接明文保存。最简单的也需要MD5处理一下再保存,Spring Security中的 BCryptPasswordEncoder也可以,它的底层是采用SHA-256 +随机盐+密钥对密码进行加密,而SHA和MD系列是一样的,都是hash摘要类的算法。
3.10 数据参数合法性校验
接口数据的安全性保证,还需要我们的系统,有个数据合法性校验,简单来说就是参数校验,比如身份证长度,手机号长度,是否是数字等等。
4. 接口性能优化方案
4.1 本地缓存
本地缓存,最大的优点是应用和cache是在同一个进程内部,请求缓存非常快,没有过多的网络开销等,在单应用不要集群支持或者集群情况下各节点无需互相通知的场景使用本地缓存比较合适。
缺点;缓存和应用程序耦合,多个应用程序无法直接共享缓存,各应用或集群的各个节点都需要维护自己的缓存,对内存是一种浪费。
常用的本地缓存框架有Guava、Caffeine等,引入jar包即可直接使用
适用场景
- 对缓存内容实效性要求不高,能够接收一定的延迟,可以设置较短过期时间,被动失效更新保持数据的新鲜度
- 缓存的内容不会改变,比如:订单号与Uid的映射关系,一旦创建就不会发生改变
注意问题
- 内存cache数据条目上限,避免内存占用过多导致应用瘫痪
- 内存中的数据一处策略
- 实际开发中最好采用成熟的开源框架,避免踩坑
4.2 分布式缓存
分布式缓存借助分布式概念,集群化部署、独立运维、荣康无上限。虽然会有网络传输损耗,但1~2ms的延迟相较其他的可以忽略。
优秀的分布式缓存系统有大家所熟知的 Memcached 、Redis。对比关系型数据库和缓存存储,其在读和写性能上的差距可谓天壤之别,Redis单节点已经可以做到 8W+ QPS。设计方案时尽量把读写压力从数据库转移到缓存上,有效保护脆弱的关系型数据库。
注意问题
- 缓存的命中率,如果太低无法起到抗压的作用,压力还是压到了下游的存储层
- 缓存的空间大小,这个要根据具体业务场景来评估,防止空间不足,导致一些热点数据被置换出去
- 缓存数据的一致性
- 缓存的快速扩容问题
- 缓存的接口平均RT,最大RT,最小RT
- 缓存的QPS
- 网络出口流量
- 客户端连接数
4.3 并行化
梳理业务流程,画出时序图,分清楚哪些是串行?哪些是并行?充分利用多核 CPU 的并行化处理能力
如下图所示,存在上下文依赖的采用串行处理,否则采用并行处理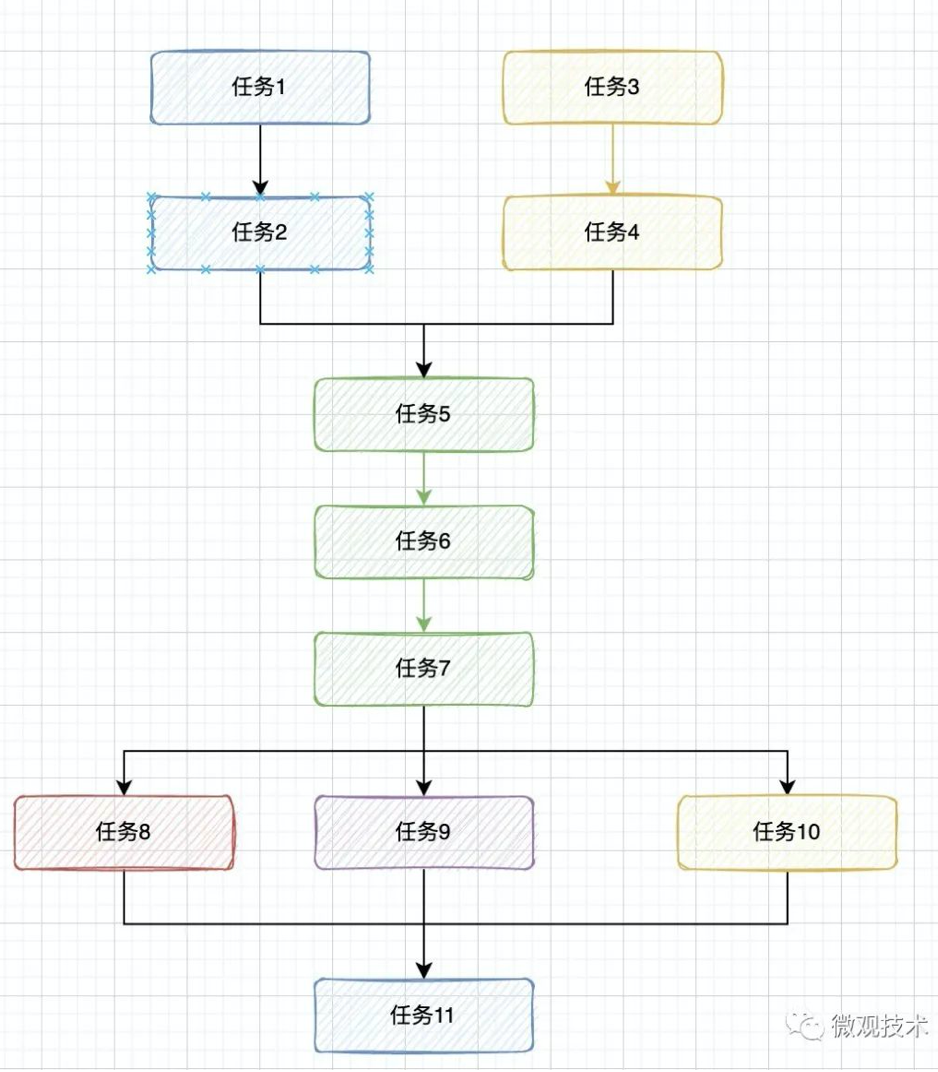
JDK 的 CompletableFuture 提供了非常丰富的API,大约有50种 处理串行、并行、组合以及处理错误的方法,可以满足我们的场景需求。
4.4 异步化
一个接口的 RT 响应时间是由内部业务逻辑的复杂度决定的,执行的流程约简单,那接口的耗费时间就越少。
所以,普遍做法就是将接口内部的非核心逻辑剥离出来,异步化来执行。
下图是一个电商的创建订单接口,创建订单记录并插入数据库是我们的核心诉求,至于后续的用户通知,如:给用户发个短信等,如果失败,并不影响主流程的完成。
我们会将这些操作从主流程中剥离出来。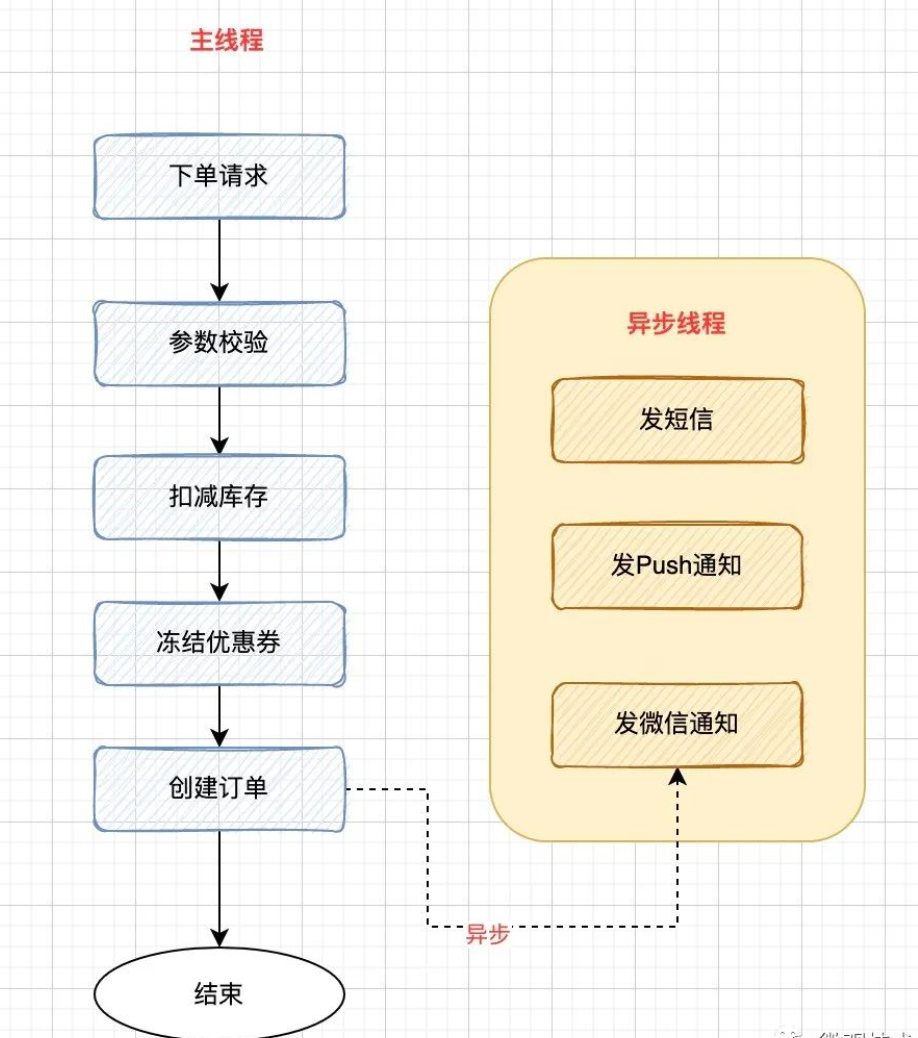
4.5 池化
TCP 三次握手非常耗费性能,所以我们引入了 Keep-Alive 长连接,避免频繁的创建、销毁连接。
池化技术也是类似道理,将很多能重复使用的对象缓存起来,放到一个池子里,用的时候去申请一个实例对象 ,用完后再放回池子里。
池化技术的核心是资源的“预分配”和“循环使用”,常见的池化技术的使用有:线程池、内存池、数据库连接池、HttpClient 连接池等
连接池的几个重要参数:最小连接数、空闲连接数、最大连接数
比如创建一个线程池:
1 | new ThreadPoolExecutor(3, 15, 5, TimeUnit.MINUTES, |
4.6 分库分表
MySQL的底层 innodb 存储引擎采用 B+ 树结构,三层结构支持千万级的数据存储。
当然,现在互联网的用户基数非常大,这么大的用户量,单表通常很难支撑业务需求,将一个大表水平拆分成多张结构一样的物理表,可以极大缓解存储、访问压力。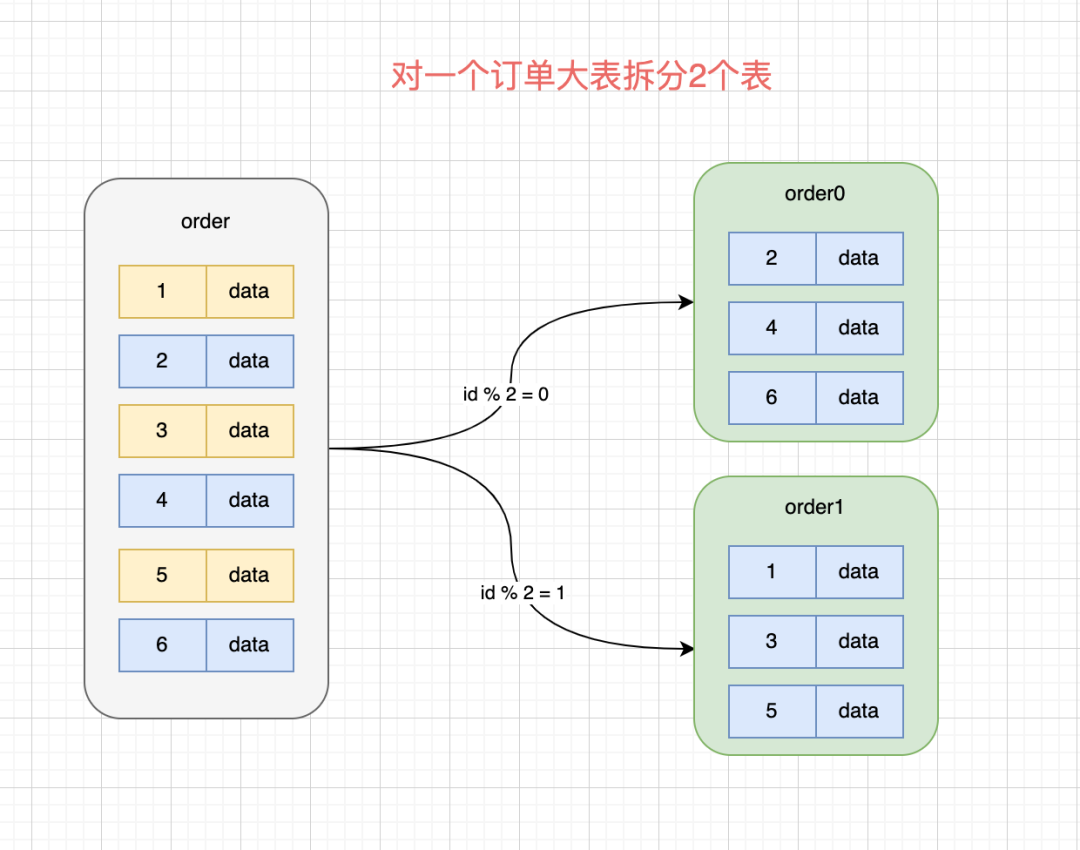
分库分表主要有两个方向:垂直和水平。
说实话垂直方向(即业务方向)更简单。
在水平方向(即数据方向)上,分库和分表的作用,其实是有区别的,不能混为一谈。
- 分库:是为了解决数据库连接资源不足问题,和磁盘IO的性能瓶颈问题。
- 分表:是为了解决单表数据量太大,sql语句查询数据时,即使走了索引也非常耗时问题。此外还可以解决消耗cpu资源问题。
- 分库分表:可以解决 数据库连接资源不足、磁盘IO的性能瓶颈、检索数据耗时 和 消耗cpu资源等问题。
如果在有些业务场景中,用户并发量很大,但是需要保存的数据量很少,这时可以只分库,不分表。
如果在有些业务场景中,用户并发量不大,但是需要保存的数量很多,这时可以只分表,不分库。
如果在有些业务场景中,用户并发量大,并且需要保存的数量也很多时,可以分库分表。
4.7 SQL 优化
虽然有了分库分表,从存储维度可以减少很大压力,但「富不过三代」,我们还是要学会精打细算,就比如所有的数据库操作都是通过 SQL 来执行。
一个不好的SQL会对接口性能产生很大影响。
比如:
- 搞了个深度翻页,每次数据库引擎都要预查非常多的数据
- 索引缺失,走了全表扫描
- 一条 SQL 一次查询 几万条数据

4.8 预先计算
有很多业务的计算逻辑比较复杂,比如页面要展示一个网站的 PV、微信的拼手气红包等
如果在用户访问接口的瞬间触发计算逻辑,而这些逻辑计算的耗时通常比较长,很难满足用户的实时性要求。
一般我们都是提前计算,然后将算好的数据预热到缓存中,接口访问时,只需要读缓存即可
4.9 事务相关
很多业务逻辑有事务要求,针对多个表的写操作要保证事务特性。
但事务本身又特别耗费性能,为了能尽快结束,不长时间占用数据库连接资源,我们一般要减少事务的范围。
将很多查询逻辑放到事务外部处理。另外在事务内部,一般不要进行远程的 RPC 接口访问,一般占用的时间比较长
@Transactional注解这种声明式事务的方式提供事务功能,容易造成大事务,引发其他的问题
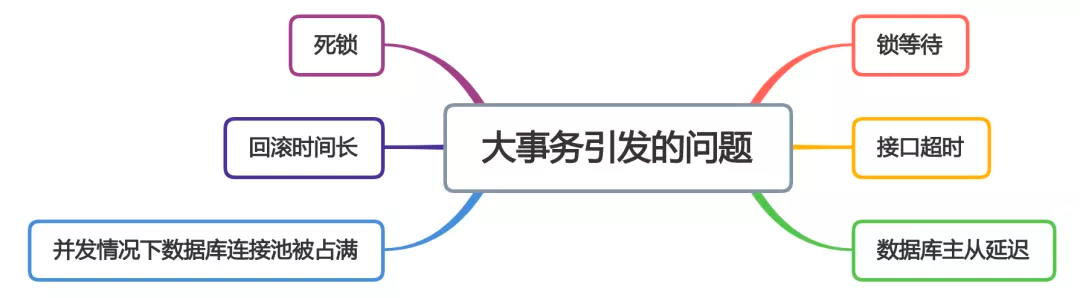
从图中能够看出,大事务问题可能会造成接口超时,对接口的性能有直接的影响。优化大事务:
- 少用@Transactional注解
- 将查询(select)方法放到事务外
- 事务中避免远程调用
- 事务中避免一次性处理太多数据
- 有些功能可以非事务执行
- 有些功能可以异步处理
4.10 海量数据处理
如果数据量过大,除了采用关系型数据库的分库分表外,我们还可以采用 NoSQL;如:MongoDB、Hbase、Elasticsearch、TiDB
NoSQL 采用分区架构,对数据海量存储能较好的支持,但是事务方面可能没那么友好。
每一个 NoSQL 框架都有自己的特色,有支持 搜索的、有列式存储、有文档存储,大家可以根据自己的业务场景选择合适的框架。
4.11 批量读写
当下的计算机CPU处理速度还是很多的,而 IO 一般是个瓶颈,如:磁盘IO、网络IO。
有这么一个场景,查询 100 个人的账户余额?
有两个设计方案:
- 方案一:开单次查询接口,调用方内部循环调用 100 次
- 方案二:服务提供方开一个批量查询接口,调用方只需查询 1 次 (更优)
数据库的写操作也是一样道理,为了提高性能,我们一般都是采用批量更新。
4.12 锁的粒度
并发业务,为了防止数据的并发更新对数据的正确性产生干扰,我们通常是采用 加锁 ,涉及独享资源每次只能是一个线程来处理。
问题点在于,锁是成对出现的,有加锁就是释放锁
对于非竞争资源,我们没有必要圈在锁内部,会严重影响系统的并发能力。
控制锁的范围是我们要考虑的重点。
4.12.1 synchronized
在java中提供了synchronized关键字给我们的代码加锁。 通常有两种写法:在方法上加锁 和在代码块上加锁。
1 | //上传文件 |
这里加锁的目的是为了防止并发的情况下,创建了相同的目录,第二次会创建失败,影响业务功能。
但这种直接在方法上加锁,锁的粒度有点粗。因为doSave方法中的上传文件和发消息方法,是不需要加锁的。只有创建目录方法,才需要加锁。
我们都知道文件上传操作是非常耗时的,如果将整个方法加锁,那么需要等到整个方法执行完之后才能释放锁。显然,这会导致该方法的性能很差,变得得不偿失。
我们可以改成在代码块上加锁了,具体代码如下:
1 | public void doSave(String path,String fileUrl) { |
样改造之后,锁的粒度一下子变小了,只有并发创建目录功能才加了锁。而创建目录是一个非常快的操作,即使加锁对接口的性能影响也不大。
最重要的是,其他的上传文件和发送消息功能,任然可以并发执行。
当然,这种做在单机版的服务中,是没有问题的。但现在部署的生产环境,为了保证服务的稳定性,一般情况下,同一个服务会被部署在多个节点中。如果哪天挂了一个节点,其他的节点服务任然可用。
多节点部署避免了因为某个节点挂了,导致服务不可用的情况。同时也能分摊整个系统的流量,避免系统压力过大。
同时它也带来了新的问题:synchronized只能保证一个节点加锁是有效的,但如果有多个节点如何加锁呢?
这就需要使用:分布式锁了。目前主流的分布式锁包括:redis分布式锁、zookeeper分布式锁 和 数据库分布式锁
4.12.2 Redis分布式锁
在分布式系统中,由于redis分布式锁相对于更简单和高效,成为了分布式锁的首先,被我们用到了很多实际业务场景当中。
使用redis分布式锁的伪代码如下:
1 | public void doSave(String path,String fileUrl) { |
跟之前使用synchronized关键字加锁时一样,这里锁的范围也太大了,换句话说就是锁的粒度太粗,这样会导致整个方法的执行效率很低。
其实只有创建目录的时候,才需要加分布式锁,其余代码根本不用加锁。
于是,我们需要优化一下代码:
1 | public void doSave(String path,String fileUrl) { |
上面代码将加锁的范围缩小了,只有创建目录时才加了锁。这样看似简单的优化之后,接口性能能提升很多。说不定,会有意外的惊喜喔。哈哈哈。
redis分布式锁虽说好用,但它在使用时,有很多注意的细节,隐藏了很多坑。以后遇到了再记录下来。
4.12.3 数据库分布式锁
mysql数据库中主要有三种锁:
- 表锁:加锁快,不会出现死锁。但锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行锁:加锁慢,会出现死锁。但锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 间隙锁:开销和加锁时间界于表锁和行锁之间。它会出现死锁,锁定粒度界于表锁和行锁之间,并发度一般。
并发度越高,意味着接口性能越好。
所以数据库锁的优化方向是:
优先使用行锁,其次使用间隙锁,再其次使用表锁。
4.13 上下文传递
当需要一个数据时,如果没有调 RPC 接口去查,比如想用户信息这种通用型接口
因为前面要用,肯定已经查过。但是我们知道方法的调用都是以栈帧的形式来传递,随着一个方法执行完毕而出栈,方法内部的局部变量也就被回收了。
后面如果又要用到这个信息,只能重新去查。
如果能定义一个Context 上下文对象,将一些中间信息存储并传递下来,会大大减轻后面流程的再次查询压力。
4.14 空间大小
创建集合List<String> lists = Lists.newArrayList();如果说,要往里面插入 1000000 个元素,有没有更好的方式?
- 方式一

结果:1000000 次插入 List,花费时间:154 - 方式二
结果:1000000 次插入 List,花费时间:134
如果我们预先知道集合要存储多少元素,初始化集合时尽量指定大小,尤其是容量较大的集合。
ArrayList 初始大小是 10,超过阈值会按 1.5 倍大小扩容,涉及老集合到新集合的数据拷贝,浪费性能。
4.15 查询优化
避免一次从 DB 中查询大量的数据到内存中,可能会导致内存不足,建议采用分批、分页查询
5. 接口设计的锦囊
别说话,先看图: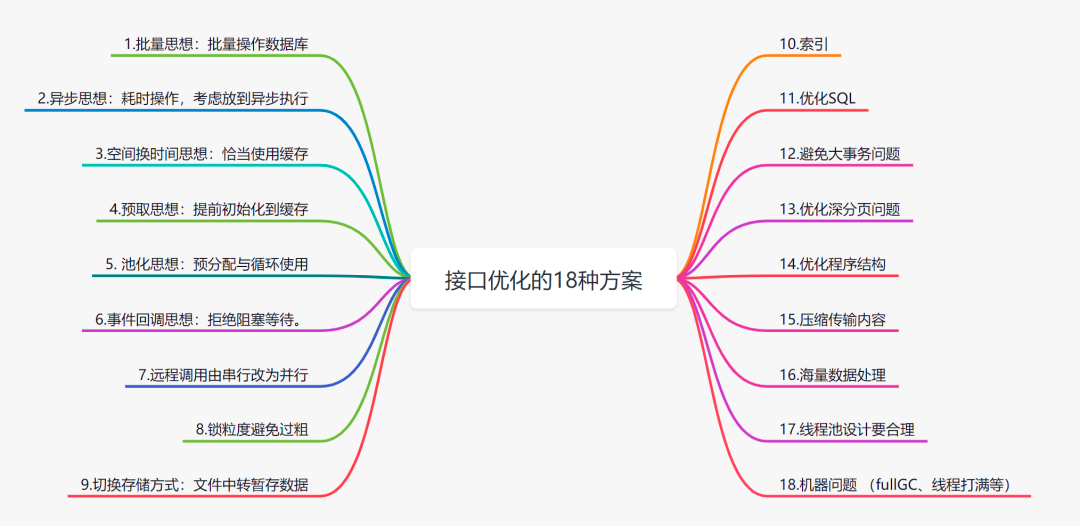
5.1 批量思想:批量操作数据库
打个比喻:假如你需要搬一万块砖到楼顶,你有一个电梯,电梯一次可以放适量的砖(最多放500),
你可以选择一次运送一块砖,也可以一次运送500,你觉得哪种方式更方便,时间消耗更少?
1 | //优化前 |
5.2 异步思想:耗时操作,考虑放到异步执行
耗时操作,考虑用异步处理,这样可以降低接口耗时。 假设一个转账接口,匹配联行号,是同步执行的,但是它的操作耗时有点长,优化前的流程: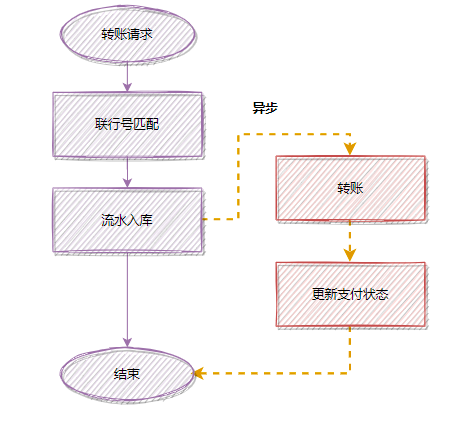
为了降低接口耗时,更快返回,你可以把匹配联行号移到异步处理,优化后: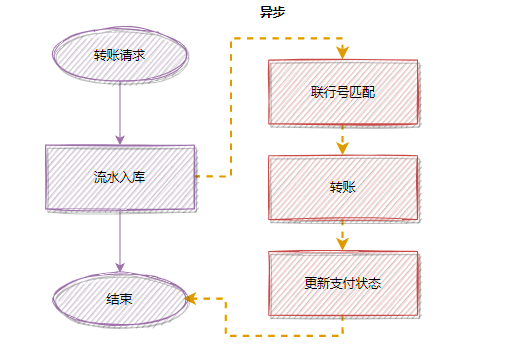
- 除了转账这个例子,日常工作中还有很多这种例子。比如:用户注册成功后,短信邮件通知,也是可以异步处理的~
- 至于异步的实现方式,你可以用线程池,也可以用消息队列实现。
5.3 空间换时间思想:恰当使用缓存。
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。缓存其实就是一种空间换时间的思想,就是你把要查的数据,提前放好到缓存里面,需要时,直接查缓存,而避免去查数据库或者计算的过程。
这里的缓存包括:Redis缓存,JVM本地缓存,memcached,或者Map等等。我举个我工作中,一次使用缓存优化的设计吧,比较简单,但是思路很有借鉴的意义。
那是一次转账接口的优化,老代码,每次转账,都会根据客户账号,查询数据库,计算匹配联行号。

优化前:每次都查数据库,都计算匹配,比较耗时,所以使用缓存进行优化
5.4 预取思想:提前初始化到缓存
预取思想很容易理解,就是提前把要计算查询的数据,初始化到缓存。如果你在未来某个时间需要用到某个经过复杂计算的数据,才实时去计算的话,可能耗时比较大。这时候,我们可以采取预取思想,提前把将来可能需要的数据计算好,放到缓存中,等需要的时候,去缓存取就行。这将大幅度提高接口性能。
5.5 池化思想:预分配与循环使用
线程池可以帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。
如果你每次需要用到线程,都去创建,就会有增加一定的耗时,而线程池可以重复利用线程,避免不必要的耗时。池化技术不仅仅指线程池,很多场景都有池化思想的体现,它的本质就是预分配与循环使用。
比如TCP三次握手,大家都很熟悉吧,它为了减少性能损耗,引入了Keep-Alive长连接,避免频繁的创建和销毁连接。当然,类似的例子还有很多,如数据库连接池、HttpClient连接池。
我们写代码的过程中,学会池化思想,最直接相关的就是使用线程池而不是去new一个线程。
5.6 事件回调思想:拒绝阻塞等待
如果你调用一个系统B的接口,但是它处理业务逻辑,耗时需要10s甚至更多。然后你是一直阻塞等待,直到系统B的下游接口返回,再继续你的下一步操作吗?这样显然不合理。
我们参考IO多路复用模型。即我们不用阻塞等待系统B的接口,而是先去做别的操作。等系统B的接口处理完,通过事件回调通知,我们接口收到通知再进行对应的业务操作即可。
5.7 远程调用由串行改为并行
假设我们设计一个APP首页的接口,它需要查用户信息、需要查banner信息、需要查弹窗信息等等。如果是串行一个一个查,比如查用户信息200ms,查banner信息100ms、查弹窗信息50ms,那一共就耗时350ms了,如果还查其他信息,那耗时就更大了。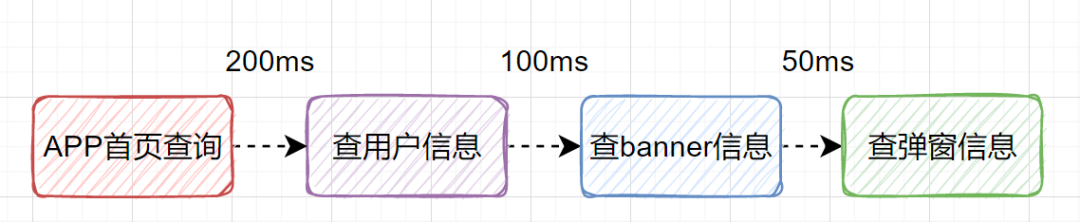
其实我们可以改为并行调用,即查用户信息、查banner信息、查弹窗信息,可以同时并行发起。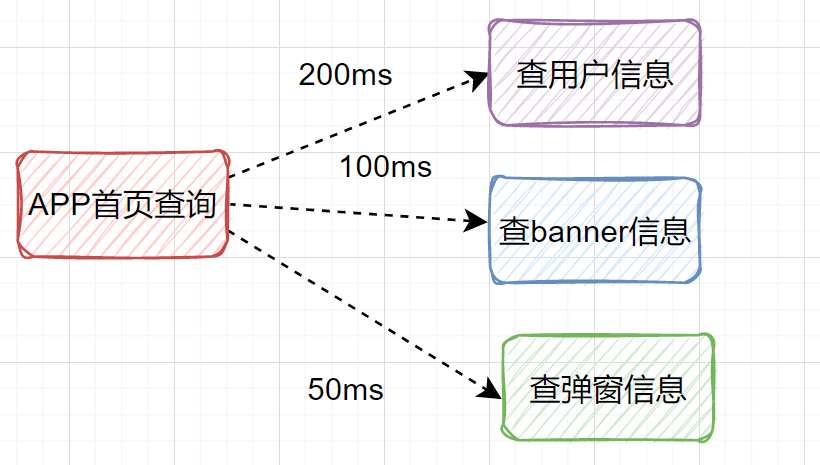
5.8 锁粒度避免过粗
在高并发场景,为了防止超卖等情况,我们经常需要加锁来保护共享资源。但是,如果加锁的粒度过粗,是很影响接口性能的。
什么是加锁粒度呢?
其实就是就是你要锁住的范围是多大。比如你在家上卫生间,你只要锁住卫生间就可以了吧,不需要将整个家都锁起来不让家人进门吧,卫生间就是你的加锁粒度。
不管你是synchronized加锁还是redis分布式锁,只需要在共享临界资源加锁即可,不涉及共享资源的,就不必要加锁。这就好像你上卫生间,不用把整个家都锁住,锁住卫生间门就可以了。
比如,在业务代码中,有一个ArrayList因为涉及到多线程操作,所以需要加锁操作,假设刚好又有一段比较耗时的操作(代码中的slowNotShare方法)不涉及线程安全问题。反例加锁,就是一锅端,全锁住:
1 | //不涉及共享资源的慢方法 |
正例:
1 | public int right() { |
5.9 切换存储方式:文件中转暂存数据
如果数据太大,落地数据库实在是慢的话,就可以考虑先用文件的方式暂存。先保存文件,再异步下载文件,慢慢保存到数据库。
之前开发了一个转账接口。如果是并发开启,10个并发度,每个批次1000笔转账明细数据,数据库插入会特别耗时,大概6秒左右;这个跟我们公司的数据库同步机制有关,并发情况下,因为优先保证同步,所以并行的插入变成串行啦,就很耗时。
优化前,1000笔明细转账数据,先落地DB数据库,返回处理中给用户,再异步转账。如图:
记得当时压测的时候,高并发情况,这1000笔明细入库,耗时都比较大。所以我转换了一下思路,把批量的明细转账记录保存的文件服务器,然后记录一笔转账总记录到数据库即可。接着异步再把明细下载下来,进行转账和明细入库。最后优化后,性能提升了十几倍。
优化后,流程图如下: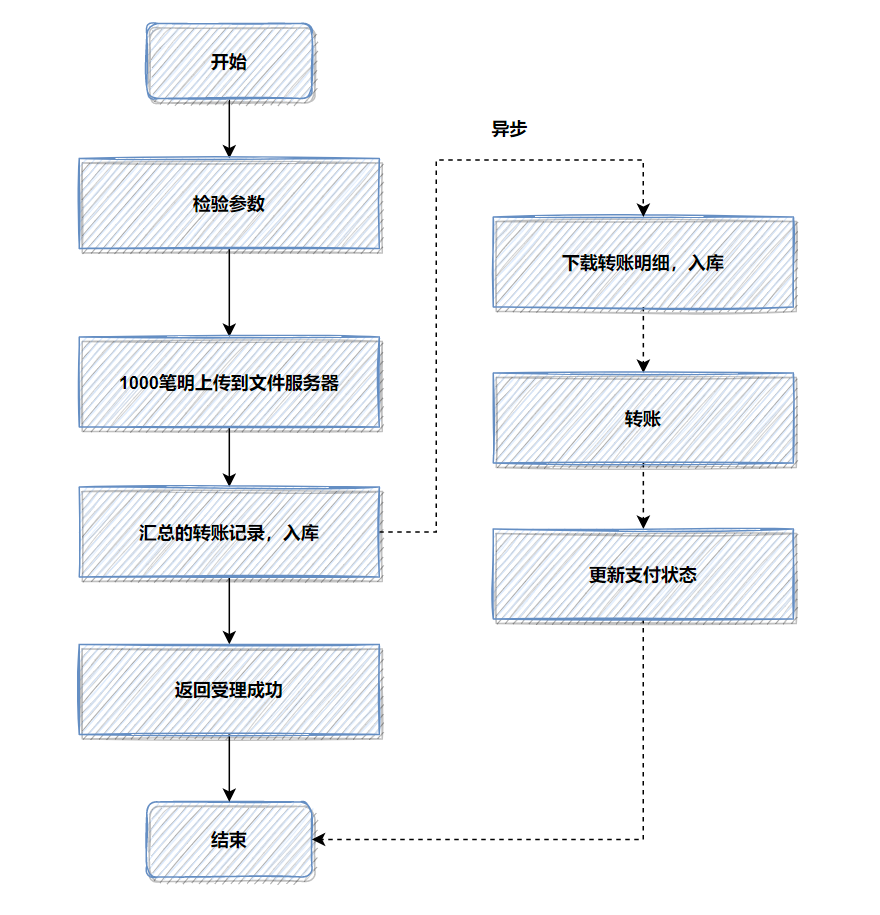
如果你的接口耗时瓶颈就在数据库插入操作这里,用来批量操作等,还是效果还不理想,就可以考虑用文件或者MQ等暂存。有时候批量数据放到文件,会比插入数据库效率更高。
5.10 索引
提到接口优化,很多小伙伴都会想到添加索引。没错,添加索引是成本最小的优化,而且一般优化效果都很不错。
索引优化这块的话,一般从这几个维度去思考:
- 你的SQL加索引了没?
- 你的索引是否真的生效?
- 你的索引建立是否合理?
5.10.1 没加索引
explain先看执行计划
1 | explain select * from user_info where userId like '%123'; |
你也可以通过命令show create table,整张表的索引情况。
1 | show create table user_info; |
如果某个表忘记添加某个索引,可以通过alter table add index命令添加索引
1 | alter table user_info add index idx_name (name); |
一般就是:SQL的where条件的字段,或者是order by 、group by后面的字段需需要添加索引。
5.10.2 索引不生效
有时候,即使你添加了索引,但是索引会失效的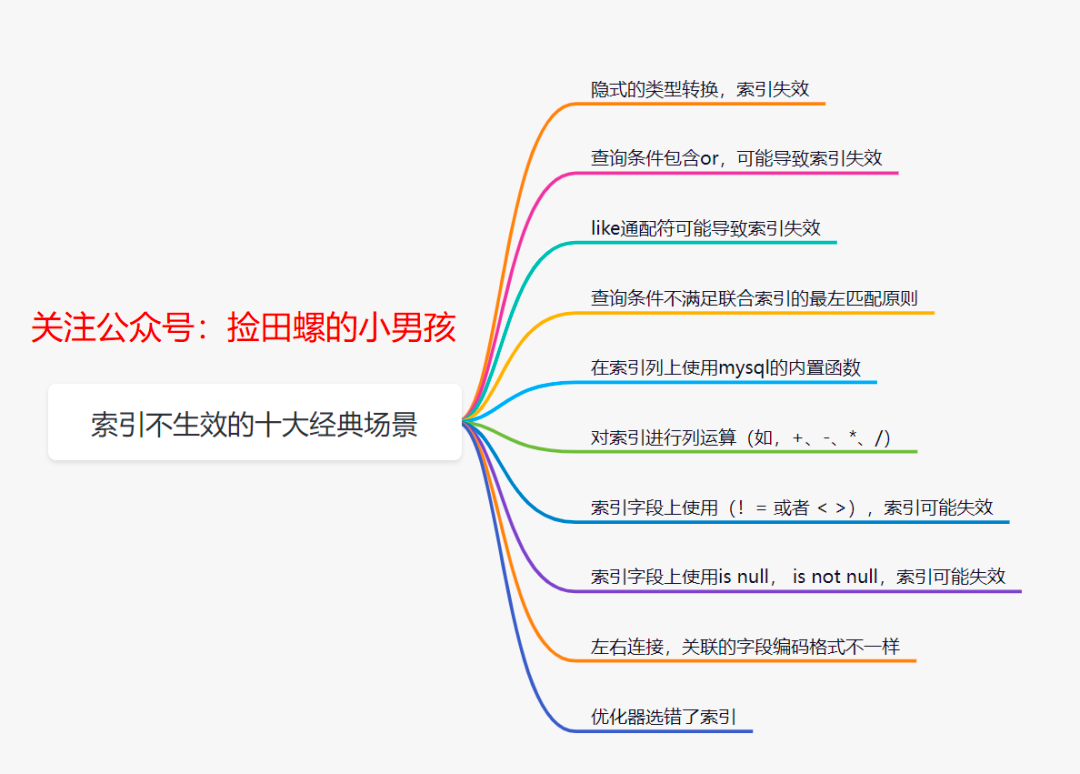
5.10.3 索引设计不合理
我们的索引不是越多越好,需要合理设计。比如:
- 删除冗余和重复索引。
- 索引一般不能超过5个
- 索引不适合建在有大量重复数据的字段上、如性别字段
- 适当使用覆盖索引
- 如果需要使用force index强制走某个索引,那就需要思考你的索引设计是否真的合理了
5.11 优化SQL
除了索引优化,其实SQL还有很多其他有优化的空间。比如这些:
5.12 避免大事务问题
为了保证数据库数据的一致性,在涉及到多个数据库修改操作时,我们经常需要用到事务。而使用spring声明式事务,又非常简单,只需要用一个注解就行@Transactional,如下面的例子:
1 |
|
这块代码主要逻辑就是创建个用户,然后更新一个通行证pass的标记。如果现在新增一个需求,创建完用户,调用远程接口发送一个email消息通知,很多小伙伴会这么写:
1 |
|
这样实现可能会有坑,事务中嵌套RPC远程调用,即事务嵌套了一些非DB操作。如果这些非DB操作耗时比较大的话,可能会出现大事务问题。
所谓大事务问题就是,就是运行时间长的事务。由于事务一致不提交,就会导致数据库连接被占用,即并发场景下,数据库连接池被占满,影响到别的请求访问数据库,影响别的接口性能。
大事务引发的问题主要有:接口超时、死锁、主从延迟等等。因此,为了优化接口,我们要规避大事务问题。我们可以通过这些方案来规避大事务:
- RPC远程调用不要放到事务里面
- 一些查询相关的操作,尽量放到事务之外
- 事务中避免处理太多数据
5.13 深分页问题
深分页问题,为什么会慢?我们看下这个SQL
1 | select id,name,balance from account where create_time> '2020-09-19' limit 100000,10; |
limit 100000,10意味着会扫描100010行,丢弃掉前100000行,最后返回10行。即使create_time,也会回表很多次。
我们可以通过标签记录法和延迟关联法来优化深分页问题, 其他优化方案可以查看博客 破解LIMIT和OFFSET分页性能瓶颈。
5.14 优化程序结构
优化程序逻辑、程序代码,是可以节省耗时的。比如,你的程序创建多不必要的对象、或者程序逻辑混乱,多次重复查数据库、又或者你的实现逻辑算法不是最高效的,等等。
我举个简单的例子:复杂的逻辑条件,有时候调整一下顺序,就能让你的程序更加高效。
假设业务需求是这样:如果用户是会员,第一次登陆时,需要发一条感谢短信。如果没有经过思考,代码直接这样写了
1 | if(isUserVip && isFirstLogin){ |
假设有5个请求过来,isUserVip判断通过的有3个请求,isFirstLogin通过的只有1个请求。那么以上代码,isUserVip执行的次数为5次,isFirstLogin执行的次数也是3次,如下:
如果调整一下isUserVip和isFirstLogin的顺序:
1 | if(isFirstLogin && isUserVip ){ |

5.15 压缩传输内容
压缩传输内容,传输报文变得更小,因此传输会更快啦。10M带宽,传输10k的报文,一般比传输1M的会快呀。
比如视频网站:如果不对视频做任何压缩编码,因为带宽又是有限的。巨大的数据量在网络传输的耗时会比编码压缩后,慢好多倍。
5.16 海量数据处理,考虑NoSQL
之前看过几个慢SQL,都是跟深分页问题有关的。发现用来标签记录法和延迟关联法,效果不是很明显,原因是要统计和模糊搜索,并且统计的数据是真的大。最后跟组长对齐方案,就把数据同步到Elasticsearch,然后这些模糊搜索需求,都走Elasticsearch去查询了。
我想表达的就是,如果数据量过大,一定要用关系型数据库存储的话,就可以分库分表。但是有时候,我们也可以使用NoSQL,如Elasticsearch、Hbase等。
5.17 线程池设计要合理
我们使用线程池,就是让任务并行处理,更高效地完成任务。但是有时候,如果线程池设计不合理,接口执行效率则不太理想。
一般我们需要关注线程池的这几个参数:核心线程、最大线程数量、阻塞队列。
- 如果核心线程过小,则达不到很好的并行效果。
- 如果阻塞队列不合理,不仅仅是阻塞的问题,甚至可能会OOM
- 如果线程池不区分业务隔离,有可能核心业务被边缘业务拖垮
5.18 机器问题 (fullGC、线程打满、太多IO资源没关闭等等)
有时候,我们的接口慢,就是机器处理问题。主要有fullGC、线程打满、太多IO资源没关闭等等。
- 之前排查过一个fullGC问题:运营小姐姐导出60多万的excel的时候,说卡死了,接着我们就收到监控告警。后面排查得出,我们老代码是Apache POI生成的excel,导出excel数据量很大时,当时JVM内存吃紧会直接Full GC了。
- 如果线程打满了,也会导致接口都在等待了。所以。如果是高并发场景,我们需要接入限流,把多余的请求拒绝掉。
- 如果IO资源没关闭,也会导致耗时增加。这个大家可以看下,平时你的电脑一直打开很多很多文件,是不是会觉得很卡。
记录这篇博客花了好几天的时间,主要是筛选一些同类型的博客,然后整理一下,在这过程中也自己也是受益良多,也更加系统性的了解、熟悉接口方面的知识。这篇博客主要是借鉴于捡田螺的小男孩 设计好接口的36个锦囊 以及 18种接口优化总结;

