1. 简介
Tika是一个内容分析工具,自带全面的parser工具类,能解析基本所有常见格式的文件,得到文件的metadata、content等内容,返回格式化信息。总的来说可以作为一个通用的解析工具。
特别是对于搜索殷勤的数据抓取和处理步骤由重要意义,Tika是Apache的Lucene项目下的子项目,在lucene的应用中可以使用tika获取大批量文档中的内容来建立索引,非常方便。Apache Tika toolkit可以自动检测各种文档(如word、ppt、xml、csv等)的类型并抽取文档的元数据和文本内容。
Tika集成了现有的文档解析库,并提供统一的接口,使针对不通类型的文档进行解析变得简单。针对搜索引擎索引、内容份、转化等非常有用
2. Tika架构
应用程序员可以很容易地在应用程序中集成Tika,它提供了一个命令行界面和图形用户洁面,比较人性化。下面就主要讲解Tika架构的四个重要模块:
语言检测机制
MIME检测机制
Parser接口
Tika Facade类
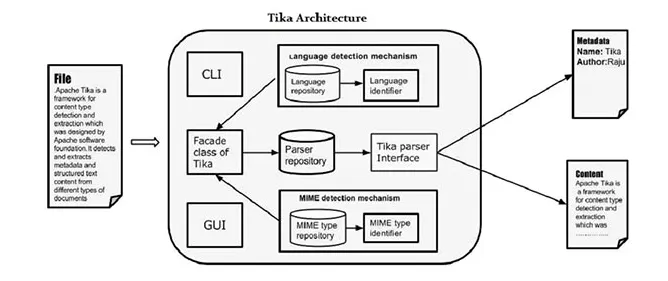
2.1 语言检测机制
每当一个文档文件被传递到Tika,它将检测在其中的语言。它接受没有语言的注释文件和功过检测该语言添加在该文件的源数据信息。支持语言识别,Tika有一类语言标识符在包org.apache.tika.language及语言识别资料库里面包含了语言检测从给定文本的算法,Tika内部使用N-gram算法语言检测
2.2 MIME检测机制
Tika可以根据MIME标准检测文档类型。Tika默认MIME类型检测是使用org.apache.tika.mime.mimeTypes。它使用org.apache.tike.detect.Detector接口大部份内容类型检测。
内部Tika使用多种技术,比如文件匹配替换、内容类型提示、魔术字节、字节编码以及其他的一些技术
2.3 解析器接口
org.apache.tika.parser解析器接口是Tika解析文档的主要接口。该接口从提取文档中的文本和元数据,并总结了其对外部用户写的解析器插件。采用不通的具体解析器类,具体为各个文档类型,Tika支持大量的文件格式。这些格式的具体类为不通格式提供支持,无论是通过试直接实现逻辑分析其或使用外部解析器库
2.4 Tika Facade类
使用的Tika facade类是从Java调用Tika的最简单和最直接的方式,而且也沿用了外观的设计模式,可以在Tika API的org.apache.tika包Tika找到外观facade类。通过实现基本实例,Tika作为facade的代理。它抽象了的Tika库的底层复杂型,例如MIME检测机制,解析器接口和语言检测机制,并提供给用户一个简单的接口来使用
3. 代码工程
通过Springboot项目使用Tika实现word转html
引入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.5.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.tika/tika-parsers -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.27</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>1.27</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>编写DTO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* @author xiaoyuge
*/
public class ConvertedDocumentDTO {
private final String contentAsHtml;
private final String filename;
public ConvertedDocumentDTO(String filename, String contentAsHtml) {
this.contentAsHtml = contentAsHtml;
this.filename = filename;
}
public String getContentAsHtml() {
return contentAsHtml;
}
public String getFilename() {
return filename;
}
public String toString() {
return new ToStringBuilder(this)
.append("filename", this.filename)
.append("contentAsHtml", this.contentAsHtml)
.toString();
}
}统一异常处理
1
2
3
4
5
6
7
8
9
10/**
* 自定义异常
* @author xiaoyuge
*/
public class DocumentConversionException extends RuntimeException {
public DocumentConversionException(String message, Exception ex) {
super(message, ex);
}
}Word转化Html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55import lombok.extern.slf4j.Slf4j;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import org.xml.sax.SAXException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.sax.SAXTransformerFactory;
import javax.xml.transform.sax.TransformerHandler;
import javax.xml.transform.stream.StreamResult;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringWriter;
public class WordToHtmlConverter {
/**
* Converts a .docx document into HTML markup. This code
* is based on <a href="http://stackoverflow.com/a/9053258/313554">this StackOverflow</a> answer.
*
* @param wordDocument The converted .docx document.
* @return
*/
public ConvertedDocumentDTO convertWordDocumentIntoHtml(MultipartFile wordDocument) throws SAXException, TikaException, TransformerConfigurationException, IOException {
log.info("Converting word document: {} into HTML", wordDocument.getOriginalFilename());
try {
InputStream input = wordDocument.getInputStream();
Parser parser = new OOXMLParser();
StringWriter sw = new StringWriter();
SAXTransformerFactory factory = (SAXTransformerFactory)
SAXTransformerFactory.newInstance();
TransformerHandler handler = factory.newTransformerHandler();
handler.getTransformer().setOutputProperty(OutputKeys.ENCODING, "utf-8");
handler.getTransformer().setOutputProperty(OutputKeys.METHOD, "html");
handler.getTransformer().setOutputProperty(OutputKeys.INDENT, "yes");
handler.setResult(new StreamResult(sw));
Metadata metadata = new Metadata();
metadata.add(Metadata.CONTENT_TYPE, "text/html;charset=utf-8");
parser.parse(input, handler, metadata, new ParseContext());
return new ConvertedDocumentDTO(wordDocument.getOriginalFilename(), sw.toString());
} catch (IOException | SAXException | TransformerException | TikaException ex) {
log.error("Conversion failed because an exception was thrown", ex);
throw new DocumentConversionException(ex.getMessage(), ex);
}
}
}请求接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class TikaController {
WordToHtmlConverter converter;
public ConvertedDocumentDTO convertWordDocumentIntoHtmlDocument( MultipartFile wordDocument) throws SAXException, TikaException, TransformerConfigurationException, IOException {
ConvertedDocumentDTO htmlDocument = converter.convertWordDocumentIntoHtml(wordDocument);
log.trace("The created HTML markup looks as follows: {}", htmlDocument);
return htmlDocument;
}
}测试
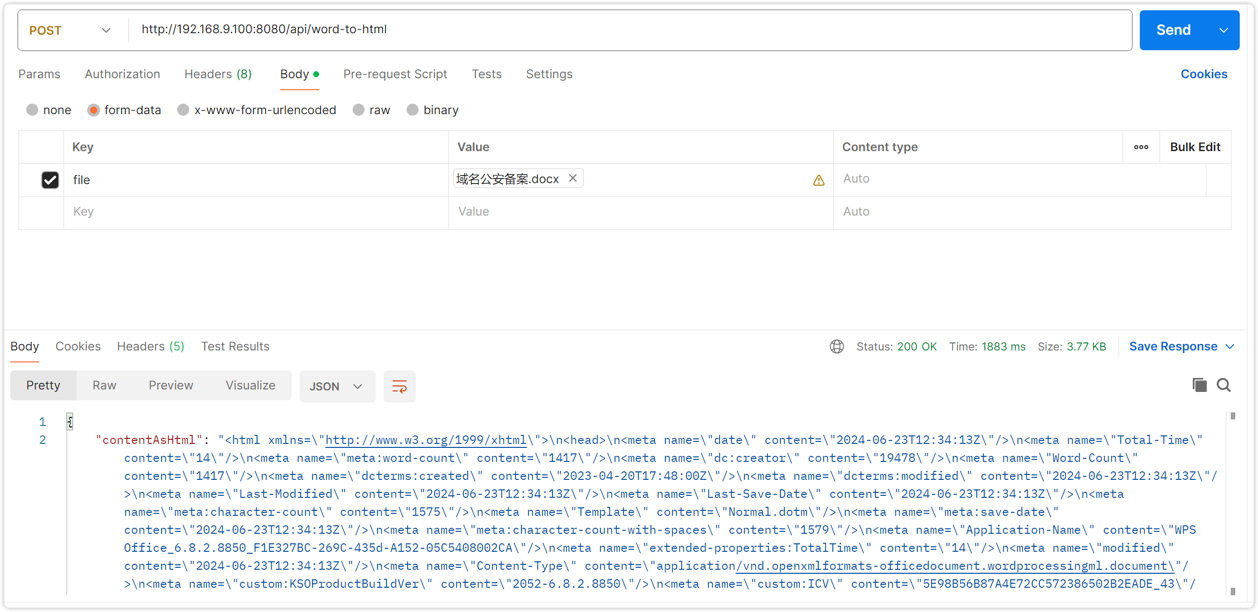
4. 其他姿势
4.1 获取文件类型和扩展名
使用Tika获取文件的类型和扩展名非常容易,只需要调用Tika类的detect()方法,并将文件传递给他即可,它会返回一个代表文档类型的字符串
1 | /** |
输出结果:
1 | 文件类型: application/vnd.ms-excel |
4.2 解析Word文档
使用Tika可以方便获取文档的内容及其元数据,Tika支持许多文档类型,包括PDF、word、Excel、PowerPoint等。
1 | /** |
输出结果:
1 | 网站备案包含两种:一种是在工信部ICP备案,另一种是公安备案。 |
4.3 提取元数据
Tika不仅可以解析文档内容,还可以获取文档的元数据(如作者、标题、描述等)
1 | /** |
4.4 解析PDF文件
PDF文件是一种非常常见的文件类型,使用Tika可以方便地解析PDF文件
1 | /** |

